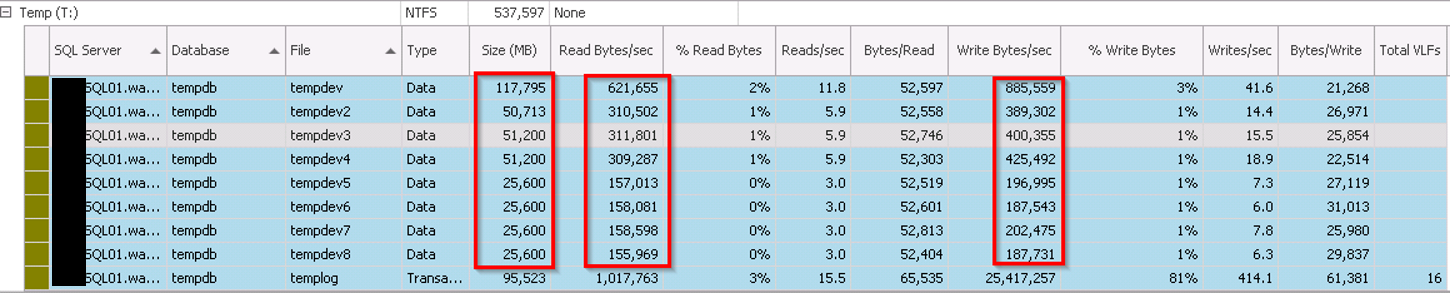
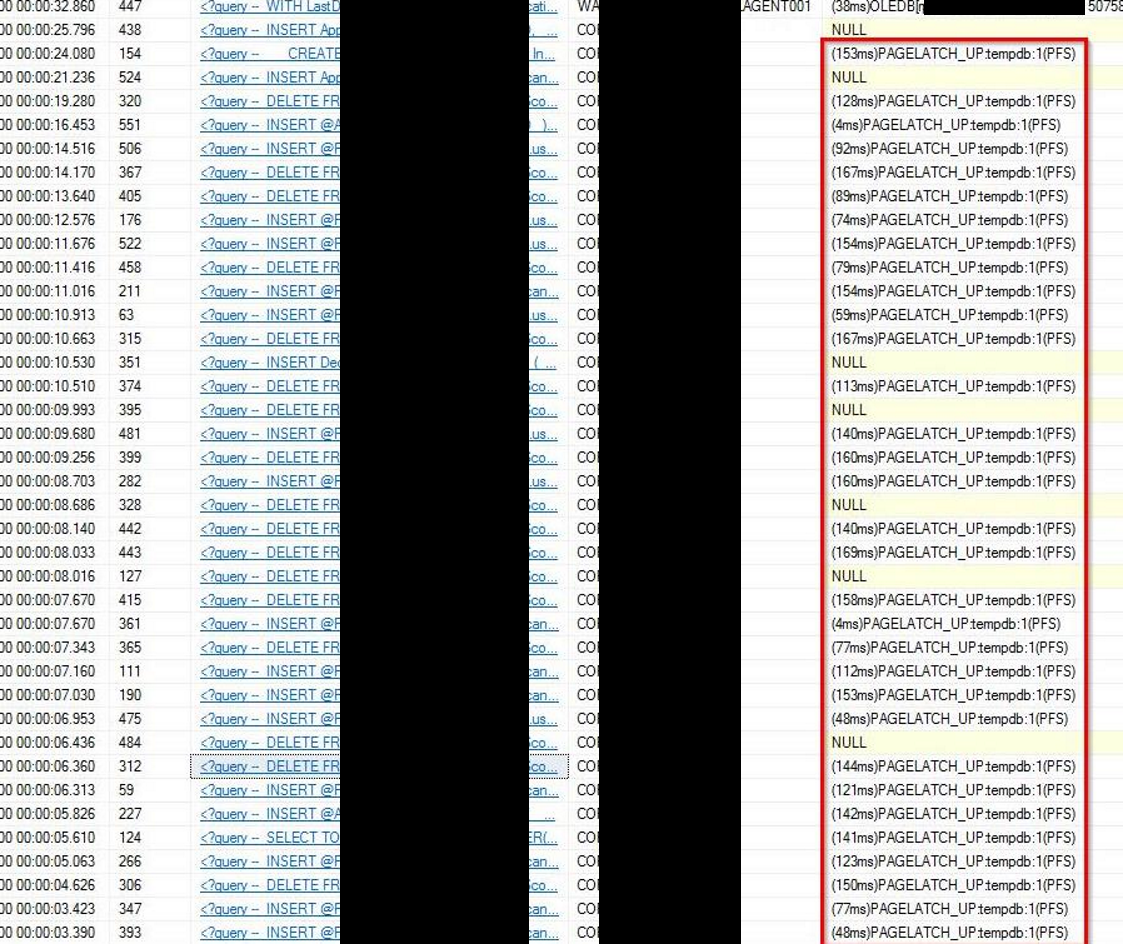
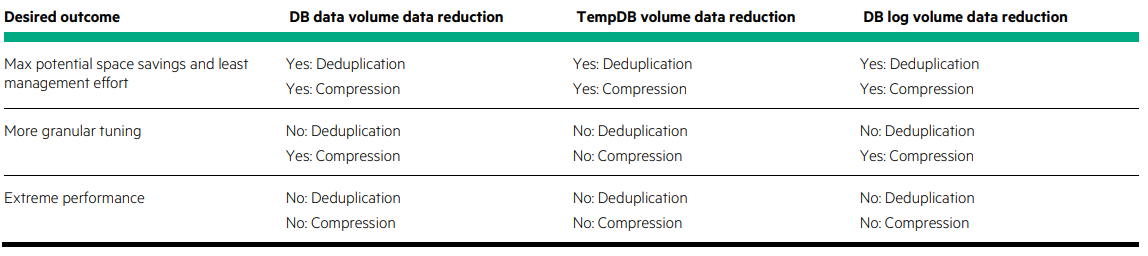
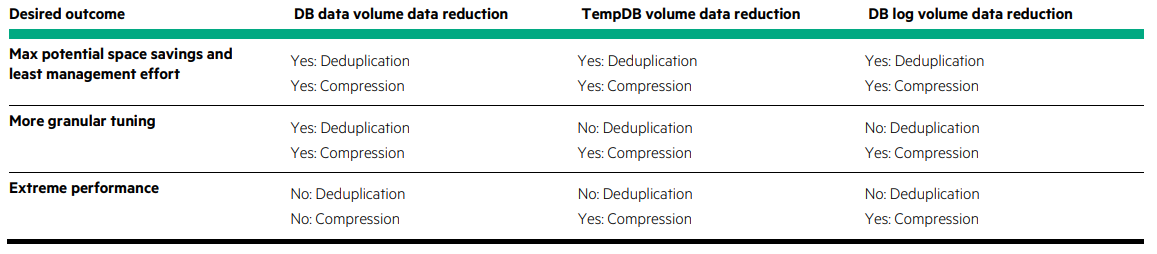
PLEASE NOTE: The generated content in this blog post has in no way shape or form been verified for correctness and purely used as an example of what can be generated, please do not take what the AI model has generated as verbatim
Well, no idea where to start with this.
I’m not an AI specialist but the growth in popularity and valuation of OpenAI since it launched it’s ChatGPT back in November 2022 has been mind boggling. I’ve only just started playing around with it and various other options after seeing some blogs, LinkedIn content and even eBooks on Power BI being written using these tools.
So, I thought I’d generate a blog post purely using copy.ai (others are available) and see how easy it is and what sort of content it turns out. No reason in particular why I chose copy.ai as opposed to OpenAI/ChatGPT
The process:
Once you have navigated to copy.ai and registered, you are presented with a number of options for generating various content types. I chose “Blog Post Wizard”

You will now be presented with a couple of text boxes whereby you can enter a blog post title, some keywords and a tone that the model can use to generate the text. I chose a series of keywords of features for SQL Server, generated from Open.AI when I asked the question, “What are the new Features of SQL Server 2022”.
NOTE: Although those keywords generated are in fact features of SQL Server, they’re not necessarily “New” features but for simplicity I just went with it.

Click Generate Outline and you will be presented with an outline for the blog post. At this point, you will notice that there are a number of new items in the list, not just those in the keywords I entered previously 😲
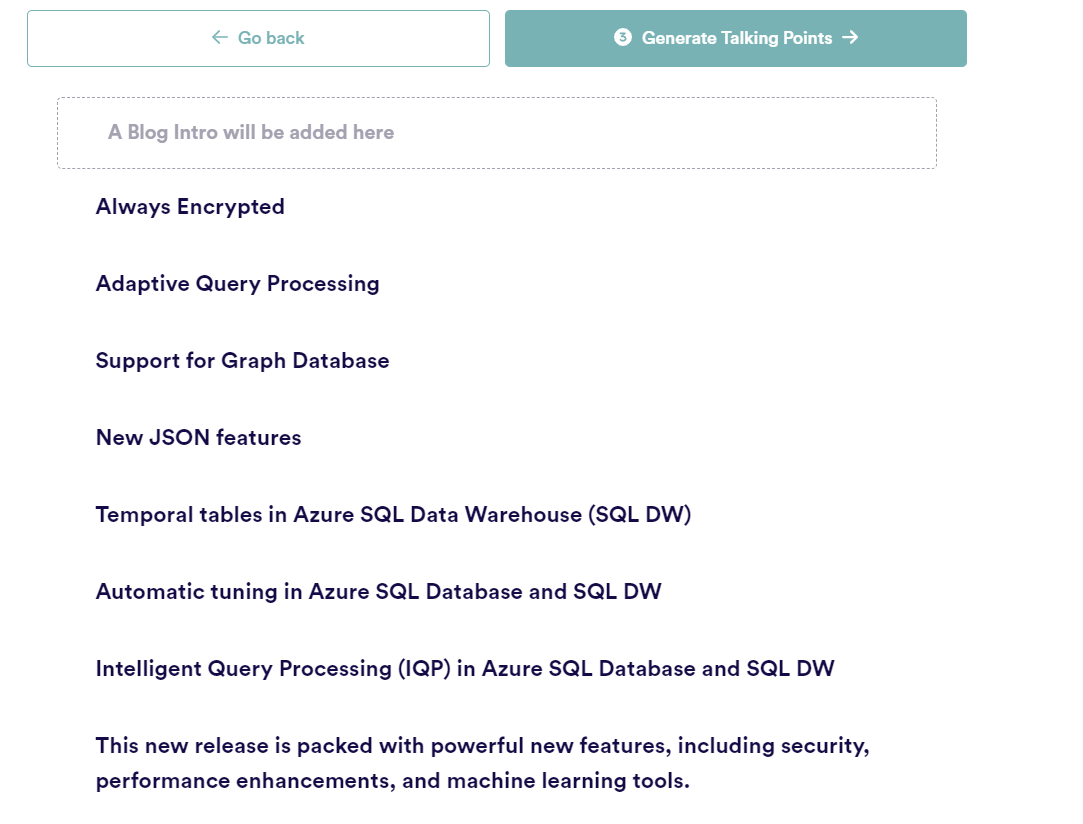
Click “Generate talking points” and you will now have a bullet point list of, erm, talking points regarding each of the Outlined points:
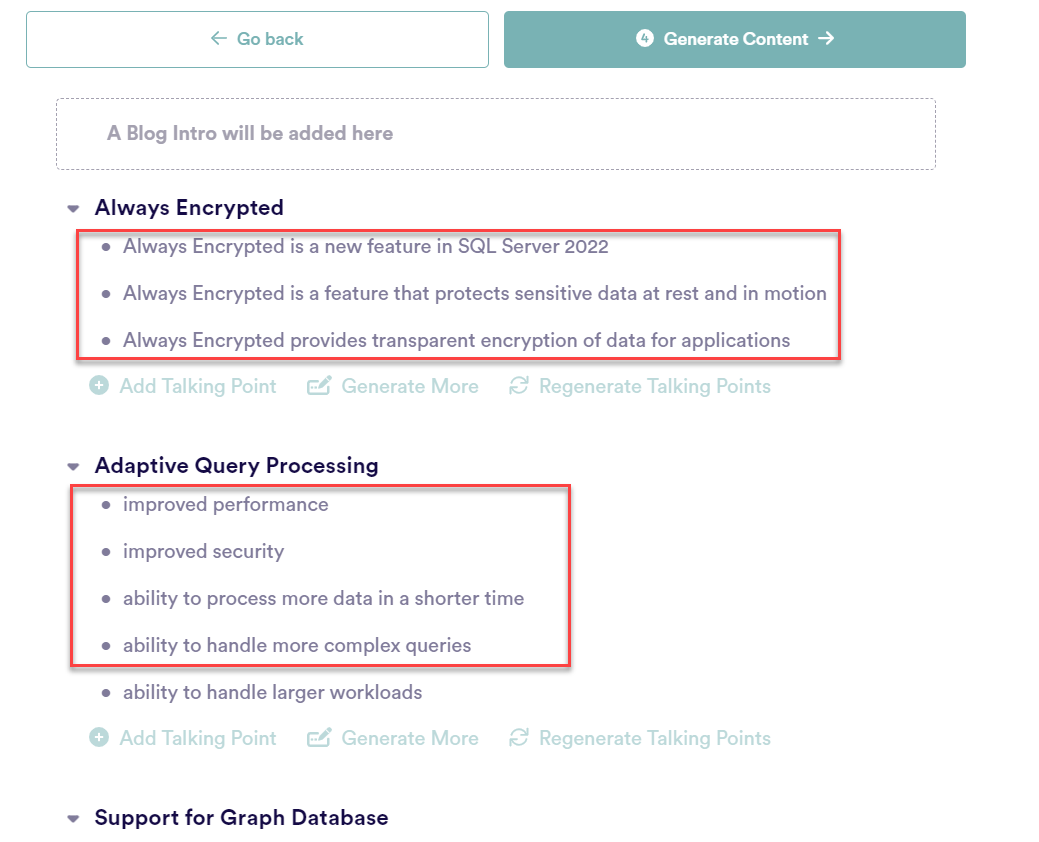
Generate Content and you will now see each of the talking points is now padded out with content, giving you the option to “Regenerate Content” for sections you’re not 100% happy with – essentially your blog post is now written!
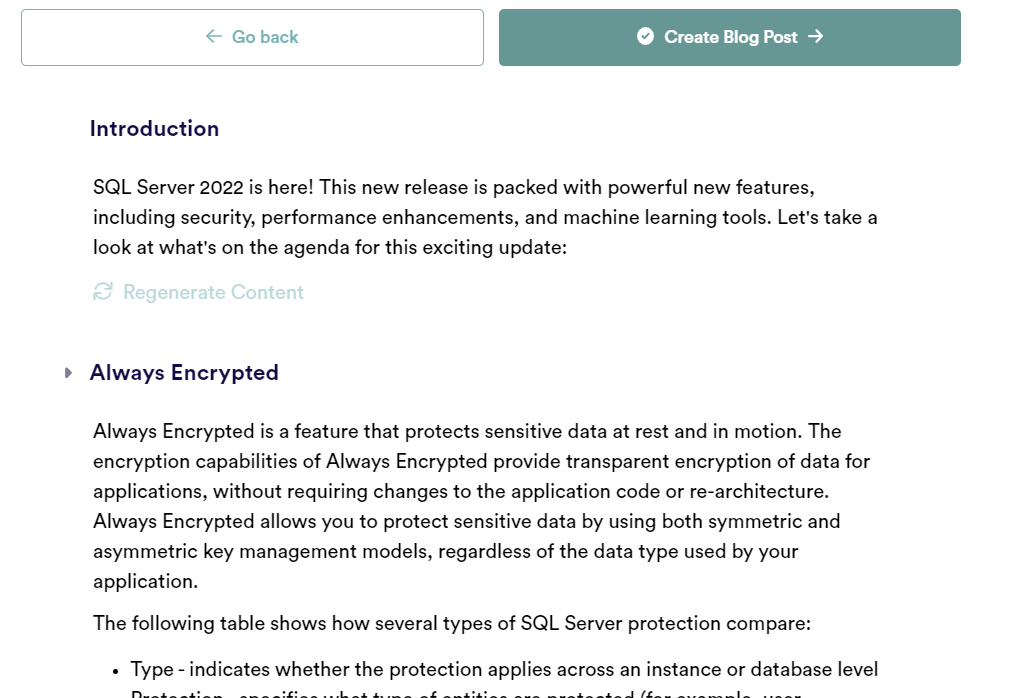
Click “Create Blog Post” and you will now have the blog post whereby you can modify / format as required😲😲😲😲😲😲😲😲😲
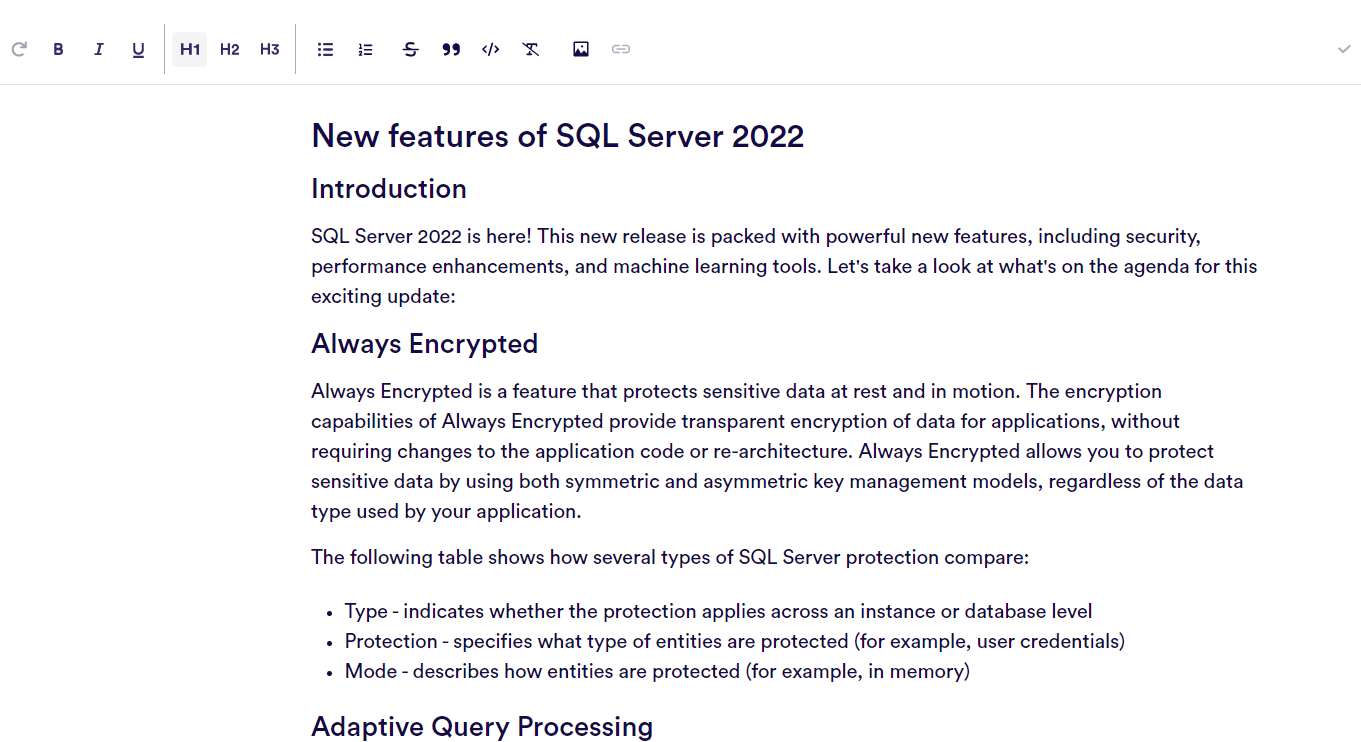
Simple as that!
Below is a copy and paste of the first time I went through it with a few regenerates of content to see the changes but I have done this twice and although both are largely the same, you can see the Introductions are slightly different:

Everything from this point, apart from the SQLGeordie Conclusion is generated content from copy.ai
<< Start copy.ai generated content >>
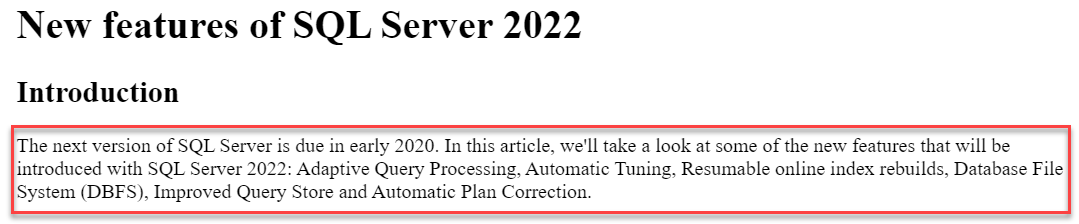
New features of SQL Server 2022
Introduction
The next version of SQL Server is due in early 2020. In this article, we’ll take a look at some of the new features that will be introduced with SQL Server 2022: Adaptive Query Processing, Automatic Tuning, Resumable online index rebuilds, Database File System (DBFS), Improved Query Store and Automatic Plan Correction.
Adaptive Query Processing
- What is Adaptive Query Processing?
Adaptive Query Processing (AQP) allows queries to be processed in a way that best suits their needs, without having to specify an exact parameterization. This means that you no longer have to worry about whether your query will use parallelism or serial execution—the database will automatically determine the best way to run your query based on the workload and hardware available at the time it runs. This capability can significantly improve query performance for applications that need high-throughput queries, including those where data volumes are growing rapidly and where servers are under heavy load. It also enables very fast responses from analytics workloads running on SQL Server 2022 clusters with many nodes running queries simultaneously in parallel mode using only one node’s resources while providing maximum throughput among all nodes running in parallel mode.
Automatic Tuning
Automatic Tuning is a feature of SQL Server 2022 that helps optimize query performance. It uses Azure Machine Learning to tune queries by learning the statistics about the data and the queries.
This feature works with Azure Machine Learning to use machine learning to optimize query performance. This can help you improve your systems based on what they have learned, rather than having someone do it manually. Automatic tuning uses the same technology as Azure SQL Database, which means that if you’re using Azure SQL Database already then this feature will be familiar when it becomes available in SQL Server 2022.
Resumable online index rebuild
One of the new features in SQL Server 2022 is resumable online index rebuild. It allows you to rebuild indexes online without stopping the database and without blocking queries.
With this feature, you can continue to use your database while the index is being rebuilt—you can even submit new queries that read from the table while it’s being rebuilt. The query will be blocked until the rebuild completes (and once it does, a completion notification will be sent back to your application).
Rebuilding indexes is important because it reduces fragmentation and improves performance across many workloads. If a table has been updated frequently and contains lots of updates but few deletes or inserts, its indexes are likely fragmented and need rebuilding regularly—it’s like having an old car with a bad oil pan: You may not notice when driving around town on sunny days, but if anything happens that pushes your engine temperature past normal operating limits (like hitting traffic or driving uphill), then things could start getting messy pretty quickly!
Database File System (DBFS)
Database File System (DBFS) is a file system that is built on top of SQL Server. It allows you to store data in files instead of tables, which can be useful for storing backup files, large datasets, and other data. With DBFS, you can access the data from various applications using standard file system APIs.
Improved Query Store
- Query Store is a feature in SQL Server that allows you to record queries, plan usage and performance details, and then use that information in the future to improve performance.
- Query Store captures information about query plans and store them in a data store. You can monitor these query plans and track how they change over time so that you can learn which changes were beneficial to your workloads.
Automatic Plan Correction
Automatic Plan Correction is a new feature in SQL Server 2022 that will improve query performance by automatically correcting the plan of a query to make it more efficient. For example, if your database has not been tuned properly and you run an inefficient query against it, Automatic Plan Correction can detect this and correct the plan of your query to make it more efficient.
In-memory OLTP enhancements
In-memory OLTP is a feature of SQL Server that allows data to be stored in memory instead of on disk. This can improve performance because there is no disk latency involved in reading and writing data.
In-memory OLTP is used for high transaction processing, real-time transactional processing, and large data sets.
SQL Server 2022 will include several new features and functions such as Adaptive Query Processing, Always Encrypted, Always On Availability Groups, and more.
- SQL Server 2022 will include several new features and functions such as Adaptive Query Processing, Always Encrypted, Always On Availability Groups, and more.
- This means that you can automatically optimize queries without having to take your hands off the keyboard. The system will run them through analysis tools to see which one is most efficient for your system to process.
Conclusion
With the release of SQL Server 2022, we are bringing new features and improvements to our customers. In addition to enhanced security, performance, and scalability features, we are also introducing innovative features such as Azure Data Sync (ADS) which enables hybrid cloud data replication between on-premises databases and Azure SQL Database instances.
<< End copy.ai generated content >>
SQLGeordie Conclusion
I haven’t read through this fully line by line to scrutinise it but from skimming it, it’s actually a pretty good attempt. All in all, it took < 5mins to generate something that would take hours to generate, review, change, re-review etc etc. I think with a full review, bit of tweaking then it could be thrown out into the wild quite easily. I personally don’t think it flows as well as a blog post probably could/should do but purely based on content, it has done a good job.
Although the AI technology itself is phenomenal and indeed, very scary to see how far we’ve come so quickly – Is this the future for content generation? I’m inclined to say it certainly will be a big part of social media content, as to whether it’ll take over technical content written by really clever people, I won’t say it will entirely replace it but it certainly opens your eyes to see what can be done with little effort and could well be used to generate blog post outlines going forward.
Let me know your thoughts on how the generated content reads for you 👍🏻