We all know that if you want SQL Server to push data into a table then you want to batch the inserts / use a bulk insert mechanism but is there a time when performance isn’t everything?
Background
Although it has its critics, SSIS is a very powerful tool for Extracting, Transforming and ultimately Loading data from and to various systems. I kind of have a love / hate relationship with SSIS, I love it but it seemingly hates me with a passion.
During a recent data migration project we had a series of packages using a stored procedure as the source and a SQL Server table as the destination. By using the OLE DB Destination task you have a series of options Data Access Modes which can provide various additional configurations. I won’t delve into all of these but have a look at the msdn link provided at the end for further information.
The ones I want to concentrate on are:
- Table or view
- Table or view – Fast Load
In short, fast load does exactly what it says on the tin, it loads data fast! This is because it is optimised for bulk inserts which we all know SQL Server thrives on, it isn’t too keen on this row-by-row lark.
Problem
Now, I won’t be providing performance figures showing the difference between running a package in fast load compared to row-by-row, this has been done to death and it is pretty much a given (in most cases) that fast load will out perform row-by-row.
What I do want to bring to your attention is the differences between the two when it comes to redirecting error rows, specifically rows that are truncated. One of the beauties of SSIS is the ability to output rows that fail to import through the error pipeline and push them into an error table for example. With fast load there is a downside to this, the whole batch will be output even if there is only 1 row that fails, there are ways to handle this and a tried and tested method is to push those rows into another OLE DB Destination where you can run them either in smaller batches and keep getting smaller or simply push that batch to run in row-by-row to eventually output the 1 error you want. Take a look at Marco Schreuder’s blog for how this can be done.
One of the issues we have exerienced in the past is that any truncation of a column’s data in fast load will not force the package to fail. What? So a package can succeed when in fact the data itself could potentially not be complete!?! Yes this is certainly the case, lets take a quick look with an example.
Truncation with Fast Load
Setup
I have provided a script to setup a table where we can test this. I will attempt through SSIS to insert data which is both below and above 5 characters in length and show the output.
USE tempdb; GO DROP TABLE IF EXISTS dbo.TruncationTest; DROP TABLE IF EXISTS dbo.TruncationTest_error; CREATE TABLE dbo.TruncationTest ( TruncationTestID INT IDENTITY(1,1), TruncationTestDescription VARCHAR(5) ) GO CREATE TABLE dbo.TruncationTest_error ( TruncationTestID INT, TruncationTestDescription VARCHAR(1000) --Make sure we capture the full value ) GO
This code will set up 2 tables, one for us to import into (TruncationTest) and another to capture any error rows that we will output (TruncationTest_error).
I set up a very quick and dirty SSIS package to run a simple select statement to output 3 rows and use the fast load data access mode:
SELECT ('123') AS TruncationTestDescription UNION ALL
SELECT ('12345') UNION ALL
SELECT ('123456789');
The OLE DB Source Editor looks like this:
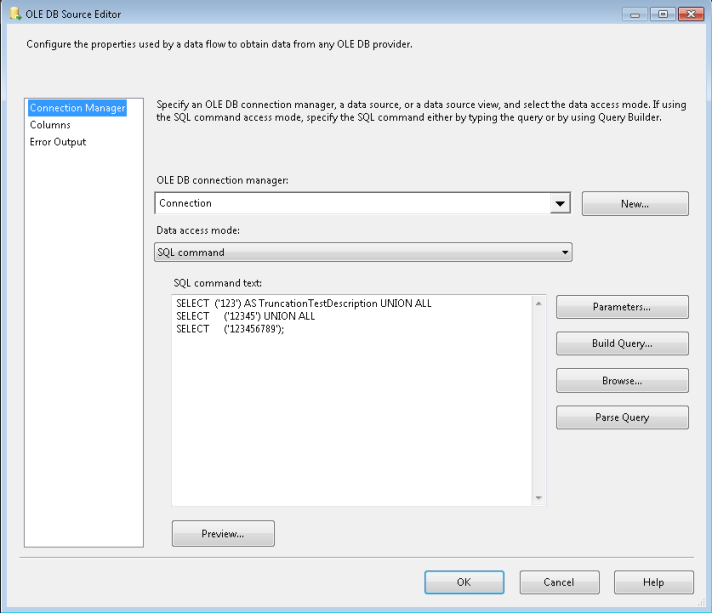
the OLE DB Destination data access mode:

Finally, this is how the package looks:
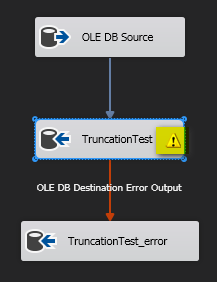
Note the truncation warning. This is easy to see when viewing a package in Visual Studio, not so easy to pick up when you are dynamically generating packages using BIML.
Let’s run it……
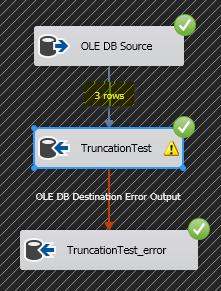
Great, 3 rows populated into the TruncationTest table, everything worked fine! So let’s check the data:
SELECT * FROM dbo.TruncationTest

Eh? What happened there???? Where’s my ‘6789’ gone from row 3???
From this example you can see that the package succeeds without error and it looks as though all rows have migrated entirely but by querying the data after the package has completed you can see that the description column has indeed been truncated.
Let’s try the same test but changing the Data Access Mode to non-fast load (ie. Row-By-Row)
Truncation with row-by-row
In this example you can see that the row with truncation is in fact pushed out to the error pipeline as you would hope and expect.
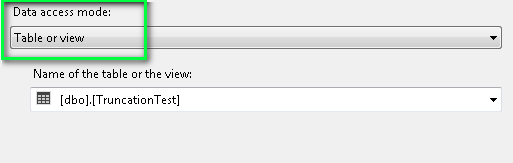
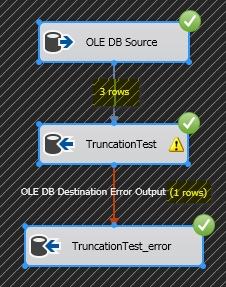
We now have 3 rows being processed but one row pushing out to the error pipeline which is what we would expect and hope for.
Let’s take a look at the output:
SELECT * FROM dbo.TruncationTest ORDER BY TruncationTestID SELECT TruncationTestDescription FROM TruncationTest_error
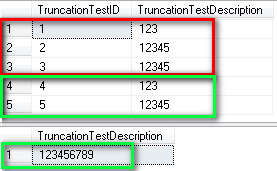
The results highlighted in red are those from the fast load, in green are the results from the row-by-row indicating that the error row was piped out to the error table.
Solution(?)
You have a few different options here:
- Not really care and push the data through in fast load and suffer the concequences
- Run in row-by-row and suffer the performance hit
- Amend the OLE DB Source Output to be the same length as the destination column and redirect error rows from there.
- Probably loads of others involving conditional splits, derived columns and/or script tasks
- Apply option #1 and make sure that relevant (automated or otherwise) testing is applied
During the recent data migration project we were involved in we chose option #5. The reasons for this are:
- We wanted to keep the BIML framework, the code and the relevant mappings as simplistic as possible
- Performance was vital….
- …..but more importantly was the validity of the data we were migrating
We already had a series of automated tests setup for each package we were running and table we were migrating and we had to add to this a series of additional automated tests to check that no data itself was being truncated.
NOTE: Option #4 was also a very valid choice for us but due to the nature of the mapping between source and destination this was not something that was easily viable to implement.
I will leave the how we implemented these test this for another blog post 🙂
Conclusion
Taking a look at the error redirect in the OLE DB Destination we can clearly see that Truncation is greyed out and no option is provided so I have to assume that it simply isn’t an option to configure it here.

I used to have a link to an article which mentions that truncation cannot be deemed an error in a bulk import operation via SSIS due to the mechanics of how it all works but for the life of me I cannot find it :(. I am hoping someone who reads this will be able to provide me with this but for now I will have to draw my own conclusions from this. The closest thing I can find is an answer from Koen Verbeeck (b|t) in an msdn forum question where he states:
The only thing you get is a warning when designing the package.
You get truncation errors when you try to put data longer than the column width in the data flow buffer, i.e. at the source or at transformations, but not at the destination apparently.
What I still don’t understand is why in tSQL you will get an error when trying to “bulk insert” (loose sense of the term……ie. using an INSERT….SELECT) data that will truncate data but SSIS does not. Hopefully someone far cleverer than me will be able to shed some light on this!
The idea behind this blog post was not to focus too much on the importance of testing any data that is moved from one place to another but I wanted to highlight how easy it is to believe that what you are migrating is all fine n dandy because the SSIS package told you so but in actual fact you could be losing some very very important data!!
You have been warned 😉
Links
- https://msdn.microsoft.com/en-us/library/ms188439.aspx
- http://blog.in2bi.com/biml/creating-a-meta-data-driven-ssis-solution-with-biml-3-creating-a-table-package/
- https://social.msdn.microsoft.com/Forums/sqlserver/en-US/49efb33f-d43a-4243-be77-ed9a360f8e85/oledb-destination-fast-load-auto-truncation?forum=sqlintegrationservices

I have ran into the same issue using dynamic BCP within SSIS. It also does not tell you when a row fails to go into the destination table but still shows as the package ran successfully. The workaround for me was using vb streamreader in the script task to get the initial row count for the flat file and comparing that to what was inserted. I then forced the SP to error out if those did not match. If you are using a table instead of a flat file you can always export to flat file first (yeah I know, tedioius and extra work) and then perform the steps above. That way you can always ensure your destination row count match your source row count.
Another option would be to use fast load, but with a smaller batch size (let’s say 20,000). If there’s an error, the entire batch is redirected to the error output, where a row-by-row OLE DB Destination tries the batch again, where all rows are committed except the one error row. This solution is a compromise between performance and error handling.
Hi Koen,
thanks for the comment.
Yes this would work if the Truncation was flagged as an error…..which it isn’t so the batched rows do not flow through the Destination error output for you to be able to do row-by-row processing on those truncated rows – the package just truncates the data and succeeds 😦
1 Pingback