I have eventually got around to start tidying up my Youtube channel since I moved it and the process made a proper mess of everything 🤦♂️
Want to get started with Docker, containers and even using SQL Server on Linux in just 12 easy , hands on steps (short videos)? If you’ve moved onto this sentence then the answer to the previous question must have been YES!
Have a look, I’ve purposely kept them as short as possible, the total time for all 12 videos is less than 90 minutes so there really is no excuse 😉
Microsoft Ignite 2020 is currently underway and if, like me, you can’t attend every session you would like to, well Microsoft have this covered with their Book of News.
There’s a ton of new stuff but this gives a great overview of all the latest information including:
I won’t go too much into what this is as you can read the article in the links above but to summarise, this will improve the experience of docker on windows:
Improvements in resource consumption
Starting up docker daemon is significantly quicker (Docker says 10s as opposed to ~1min previously)
Avoid having to maintain both Linux and Windows build scripts
Improvements to file system sharing and boot time
Allows access to some cool new features for Docker Desktop users.
Some of these are improvements we’ve been crying out for over the last couple of years so in my opinion, they’re a very welcome addition.
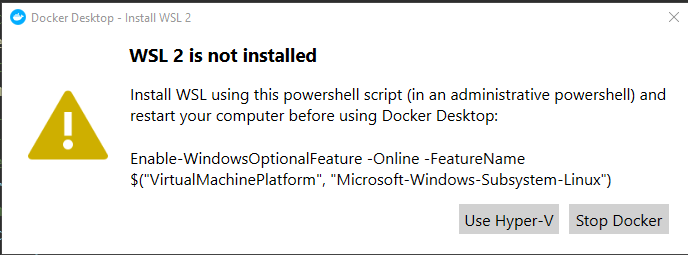
In order to get started using WSL2, there’s a couple of steps you need to run through which I’ll try and show below with a few screen shots.
Or you can go to the windows features and enable it manually:
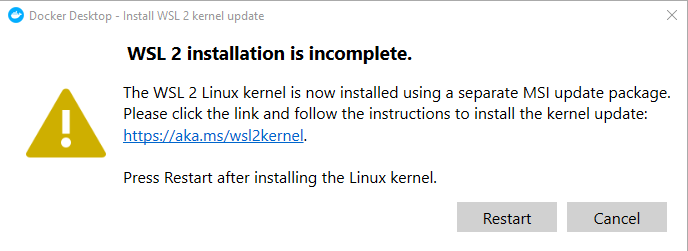
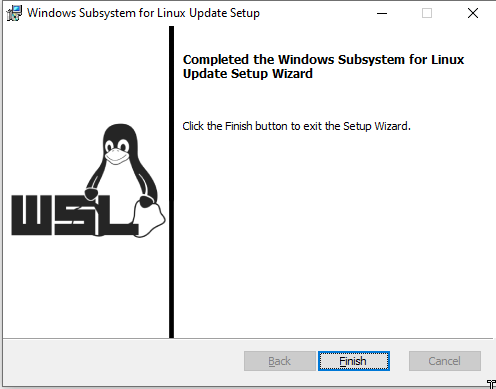
Once you have done this you will be prompted to install the Linux Kernel update package (See downloads). You can reboot before doing this (another reboot may be required after) but I managed to install it and just do a single reboot:
Need to run the Linux kernel update and restartRun the update executable
Takes about 2 seconds to update
Update now complete
Depending on your setup, there may be a couple of additional steps if you follow this link:
Checking
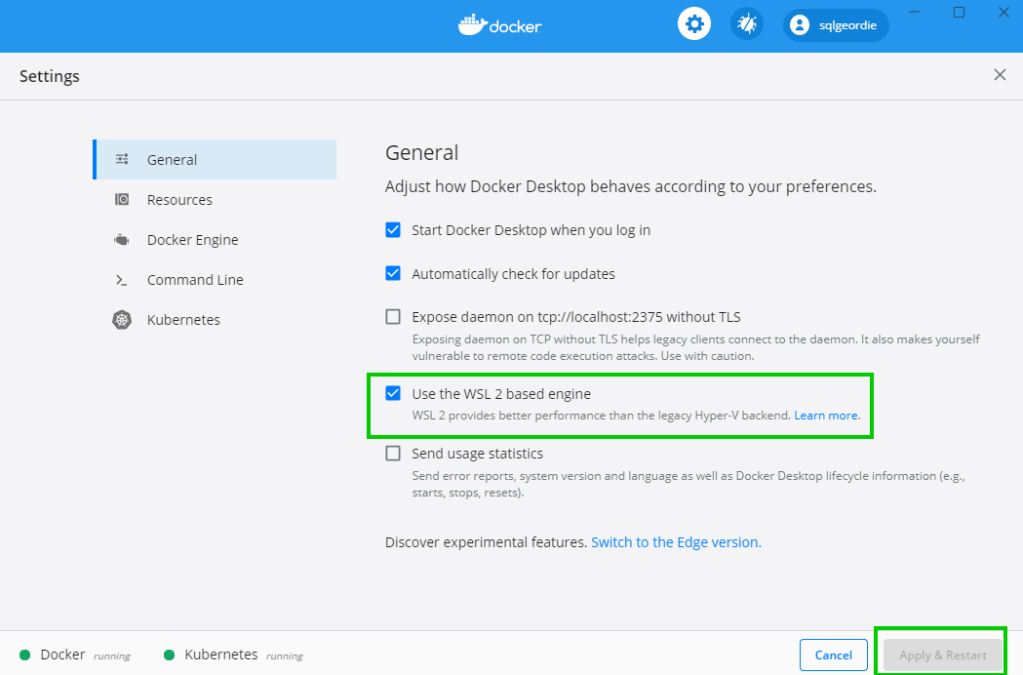
Open the Docker settings and you should now see the option to use the WSL 2 based engine:
Select it and restart docker
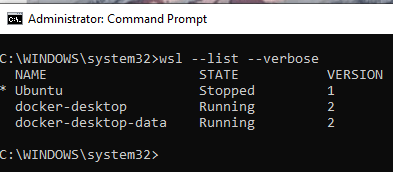
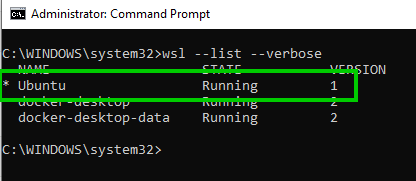
If you wish to see what version of WSL you have then you can run the command below in an elevated command prompt:
wsl --list --verbose
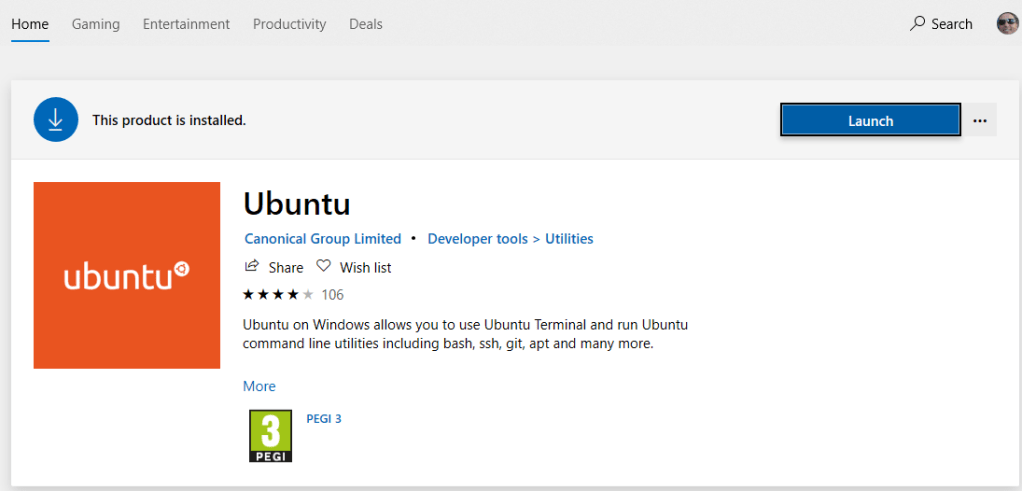
I already have the Ubuntu distribution installed so I didn’t have to do this, you may need to install this:
If you click launch then the dstro will start:
Run SQL Server on Linux
docker run -e "ACCEPT_EULA=Y" `
-e "SA_PASSWORD=P@ssword1" `
--cpus="2" `
--name SQLLinuxLocal -d `
-p 1433:1433 `
<<Put Your Image Name here>>
docker ps -a
I can’t say too much about the various performance improvements so far but the daemon startup is certainly a lot quicker than previously. Perhaps some testing of the performance is in order and another blog post……. 😜
Pretty much anything and everything that you would need for a SQL Server, Azure, AWS, GCP, Power BI etc demo dataset can be found on kaggle. The search facility is easy to use and you can also filter on the particular file type and license you want. I also like the “quicklook” option so you can quickly check to see if indeed it is the sort of data you want as opposed to having to download the data, open it and then realise it’s nothing like what you are after.
I never knew a lot about kaggle and to be honest, other than being able to get datasets from it, I never had a need to. Taken from wikipedia, “Kaggle, a subsidiary of Google LLC, is an online community of data scientists and machine learning practitioners. Kaggle allows users to find and publish data sets, explore and build models in a web-based data-science environment, work with other data scientists and machine learning engineers, and enter competitions to solve data science challenges.“
It’s actually no surprise that they’re a subsidiary of Google when you look at most if not all of Google’s datasets, they all seem to link to kaggle….
I’ve included a couple of useful datasets that I’ve used in the past, hopefully you’ll find them useful also:
For most people on the planet with internet access, the first place to visit when looking for anything on the web is Google……….other search engines are available. Not only can you search using the standard search engine but they have various spin offs specific for searching datasets.
Google tracks dateset searches, allows you to explore these and provide the ability to download the data either direct from one of their charts or by providing back links to the site in which it came from. Chances are, kaggle will be one of them which is quite obvious when they are a subsidiary of Google LLC 🙂
There are various places within google to search the datasets, depending on what it is you’re looking for, below are some examples:
This is just a short overview page of various dataset sources I’ve used in the past for usage in my SQL Server, Azure, AWS and Power BI demo’s. Most if not all of these are free as I don’t like paying for stuff and there are some whereby you can generate your own data if there is something more specific you need……..just be careful as although its “randomly” generated, I have had issues where I pushed the files to github and as it happens, one of the email addresses randomly generated was that of an employee of a company which I’d never heard of. Pure chance (I believe) but something to be mindful of if that is your intention for use.
Pretty much anything and everything that you would need for a SQL Server, Azure, AWS, GCP, Power BI etc demo dataset can be found on kaggle. The search facility is easy to use and you can also filter on the particular file type and license you want. I also like the “quicklook” option so you can quickly check to see if indeed it is the sort of data you want as opposed to having to download the data, open it and then realise it’s nothing like what you are after.
For most people on the planet with internet access, the first place to visit when looking for anything on the web is Google……….other search engines are available. Not only can you search using the standard search engine but they have various spin offs specific for searching datasets.
If there is a specific dataset you are looking for, with specific column names and data types then this is a useful tool. Data is restricted to 100 rows initially unless you sign up / donate but worth a look:
At the time of writing there are 54,846 datasets available on here. Some are a bit bizarre (See below) and are specific to the UK so unless you’re looking for that kind of thing, it may not be the place for you.
Other very specific examples (apart from that below) I’ve found are “NHS Bassetlaw CCG Expenditure over £25K” and “Planned road works on the HE road network“………..
MSBuild 2020 is currently underway and if, like me, you can’t attend every session you would like to, well Microsoft have this covered with their Build Book of News.
This gives a great overview of all the latest information including:
Everyone loves a demo. When I say everyone, I mean I personally love seeing a demo in a session which is why 99% of any sessions I present will have at least one demo. This is a risky business, especially when dealing with Cloud stuff and conference wifi which is why I always record my demo’s in case they’re ever needed.
Those that know me know that I’m tight and don’t like spending money on stuff that I really need and tend to waste it on cars and watches instead so when it comes to recording I use the FREE opensource software Open Braoadcasting Software (OBS). This software is more than I’d ever need for recording and did I mention, it’s FREE!!
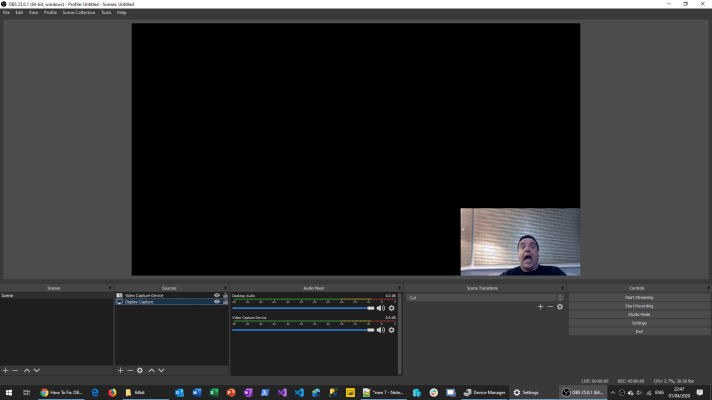
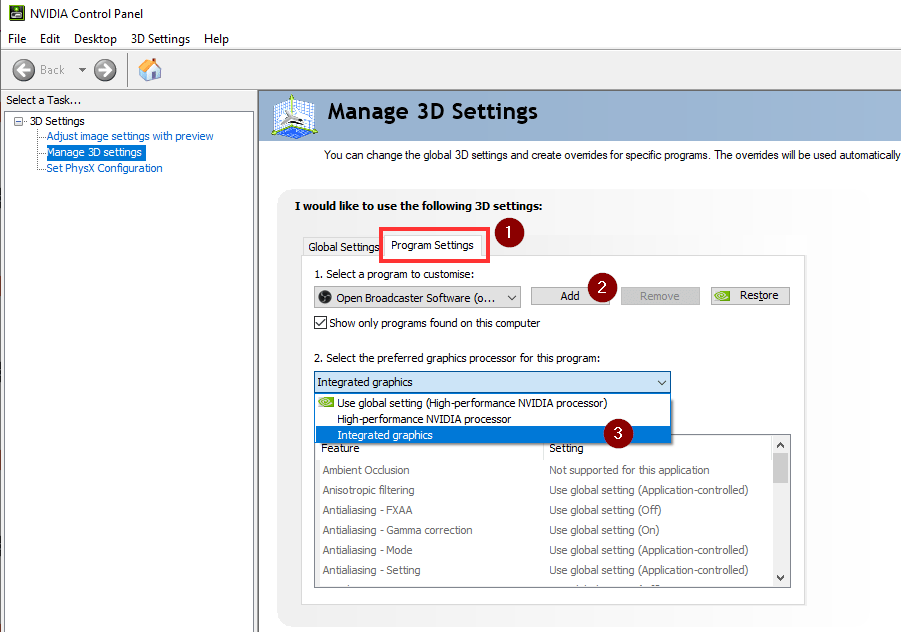
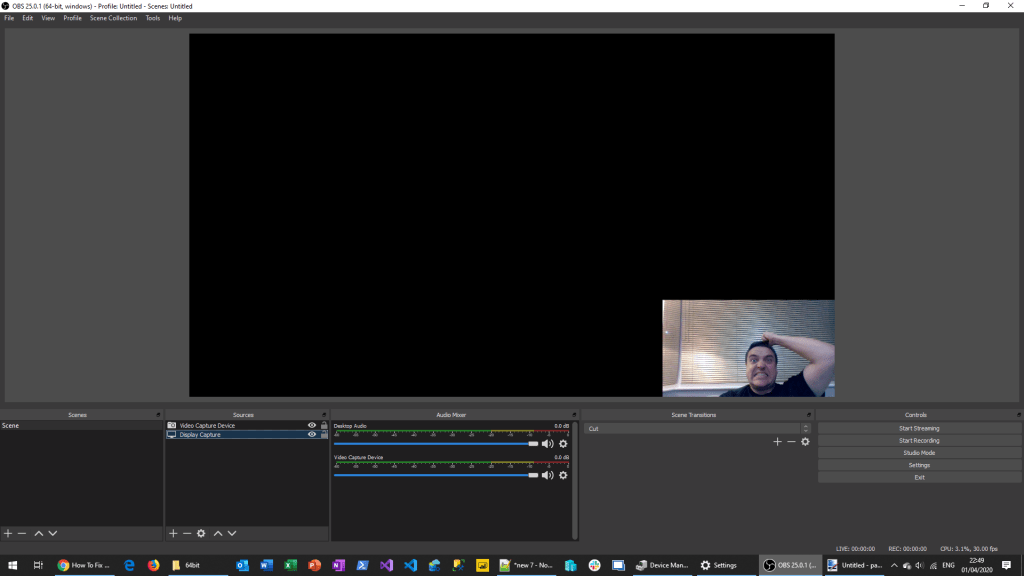
However, there has always been a bit of an issue with getting it to work. Especially for those fortunate to have a separate GPU. My laptop has a NVIDIA Quadro P1000 GPU, not the best out there but it came with the beast and does a job for me. This however is where the issue begins. When you have a separate GPU the software doesn’t know which one to use so when you fire up OBS and choose your Display Capture (ie. screen to record) you will see nothing but a black screen. You can see by the shock on my face that I’ve seen this before but updates seem to reset the changes you need to make (see further down):
Now, the fix used to be very simple, you would:
Open the NVIDIA control panel
Click on “Program Settings” tab
Choose the Open Broadcaster Software in “Select a program to Customise”
Change the preferred graphics processor to “Integrated Graphics”
Click Apply and re-open OBS
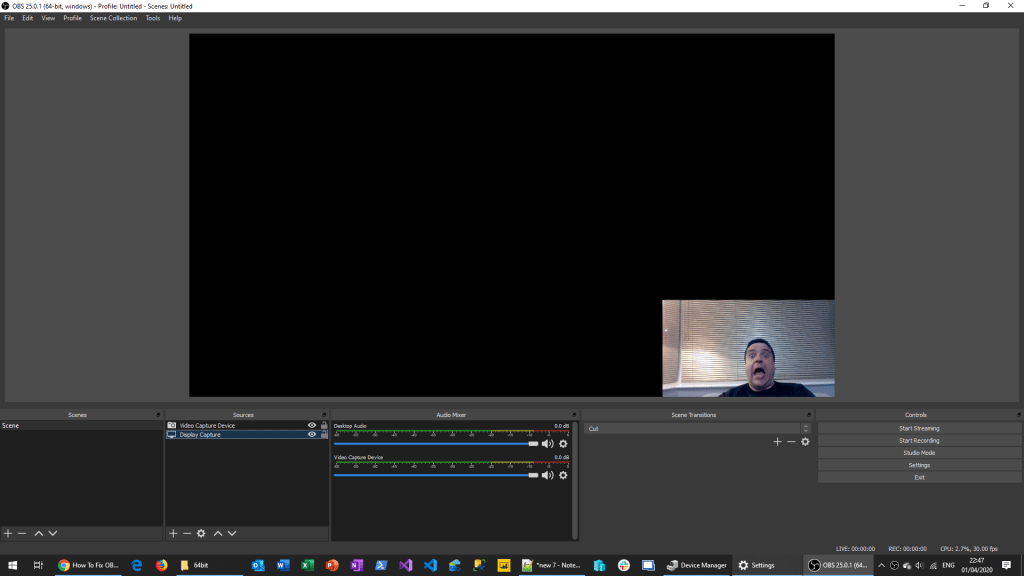
However, recent updates to either windows, NVIDIA and/or OBS has meant that this alone no longer works and you will end up tearing your hair out as per image below
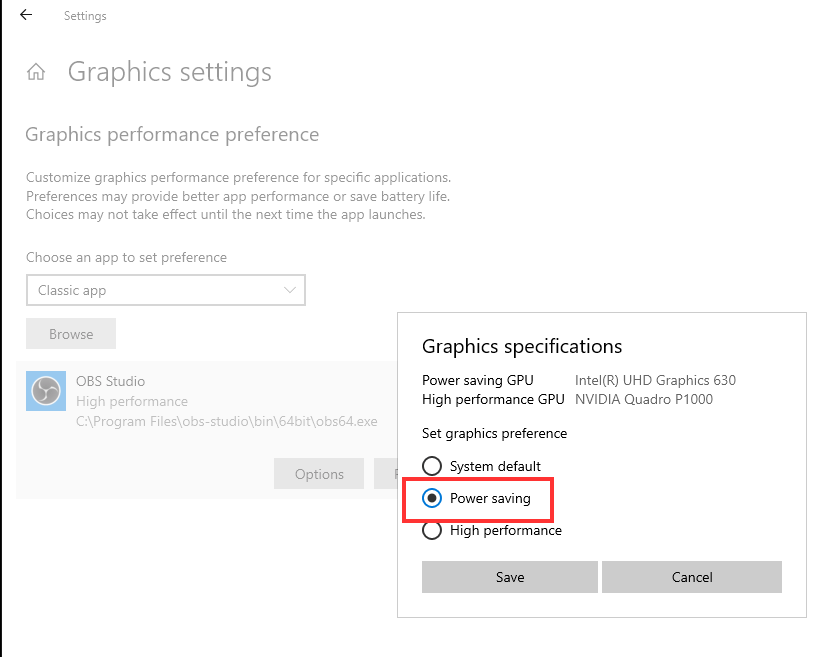
There is now an additional step you need to undertake which is to change the OBS exe to run in “Power Saving” mode.
To do this, navigate to Settings–>Graphics Settings and Browse to the OBS exe which can be found at “C:\Program Files\obs-studio\bin\64bit”. Once selected, click Options and choose “Power Saving” for the Graphics Specification as per image below:
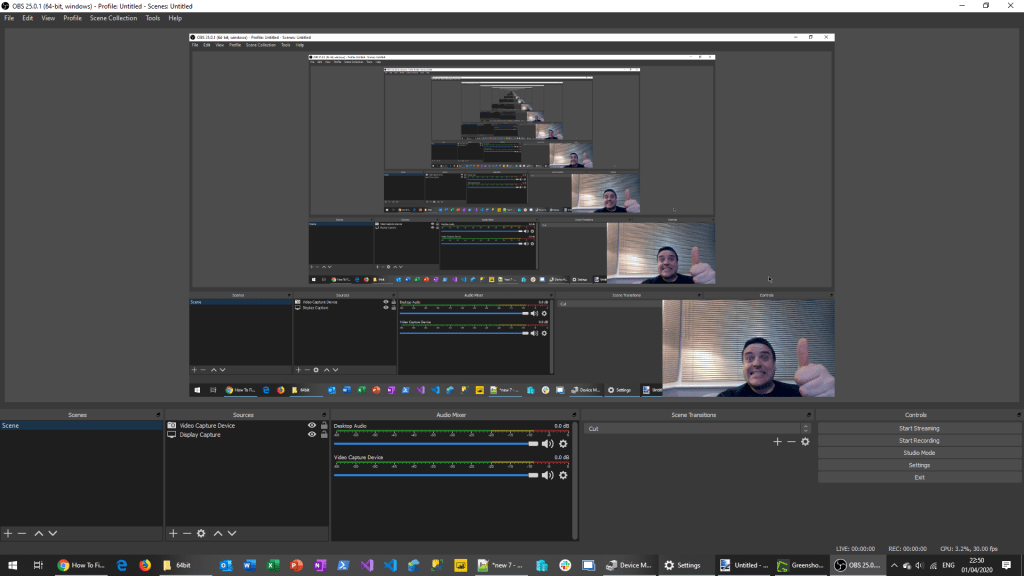
Once you have saved this then the screen Capture should now show the screen you are wishing to record you demo’s on and we’re in a happy place :).
As to why this is now required, I really don’t know at the moment and I’m sure in a few months time there’ll be something else which stops it from working.
Hopefully this helps others and if nothing else, will act as a reference guide for when I have to do this again in a few months and will have forgotten the process!
We have all now had a play around with Docker and Containers or at least heard about them.
This demo heavy session will walk through some of the challenges around managing container environments and how Kubernetes orchestration can help alleviate some of the pain points.
We will be talking about what Kubernetes is and how it works and through the use of demos we will:
Highlight some of the issues with getting setup (Specifically Minikube on Ubuntu),
Deploying/Updating containers in Kubernetes (on-Prem as well as AKS using Azure DevOps)
Upcoming and previous speaking engagements. Links to slides and demo’s can always be found on github or youtube. If you would like me to speak at your event whether in person or remotely then please contact me.




![Windows Features
Turn Windows features on or off
O
To turn a feature on, select its check box. To turn a feature off, clear its
check box. A filled box means that only pat of the feature is turned on.
D TFTP Client
Z] Virtual Machine Platform
Windows Hypervisor Platform
Windows Identity Foundation 3.5
Z] Windows PowerSheII 2.0
Windows Process Activation Service
Windows Projected File System
Windows Subsystem for Linux
Windows TIFF Filter
Work Folders Client
Cancel](https://chrisjarrintaylor.co.uk/wp-content/uploads/2020/08/image-3.png?w=422)