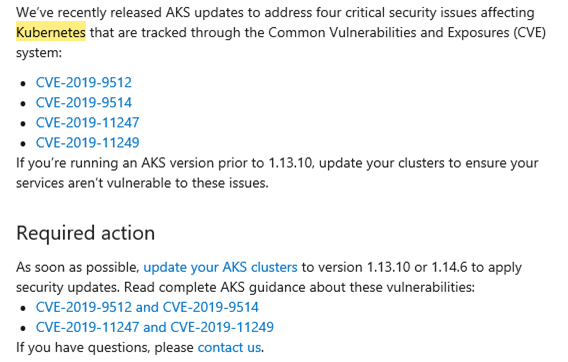
Introduction
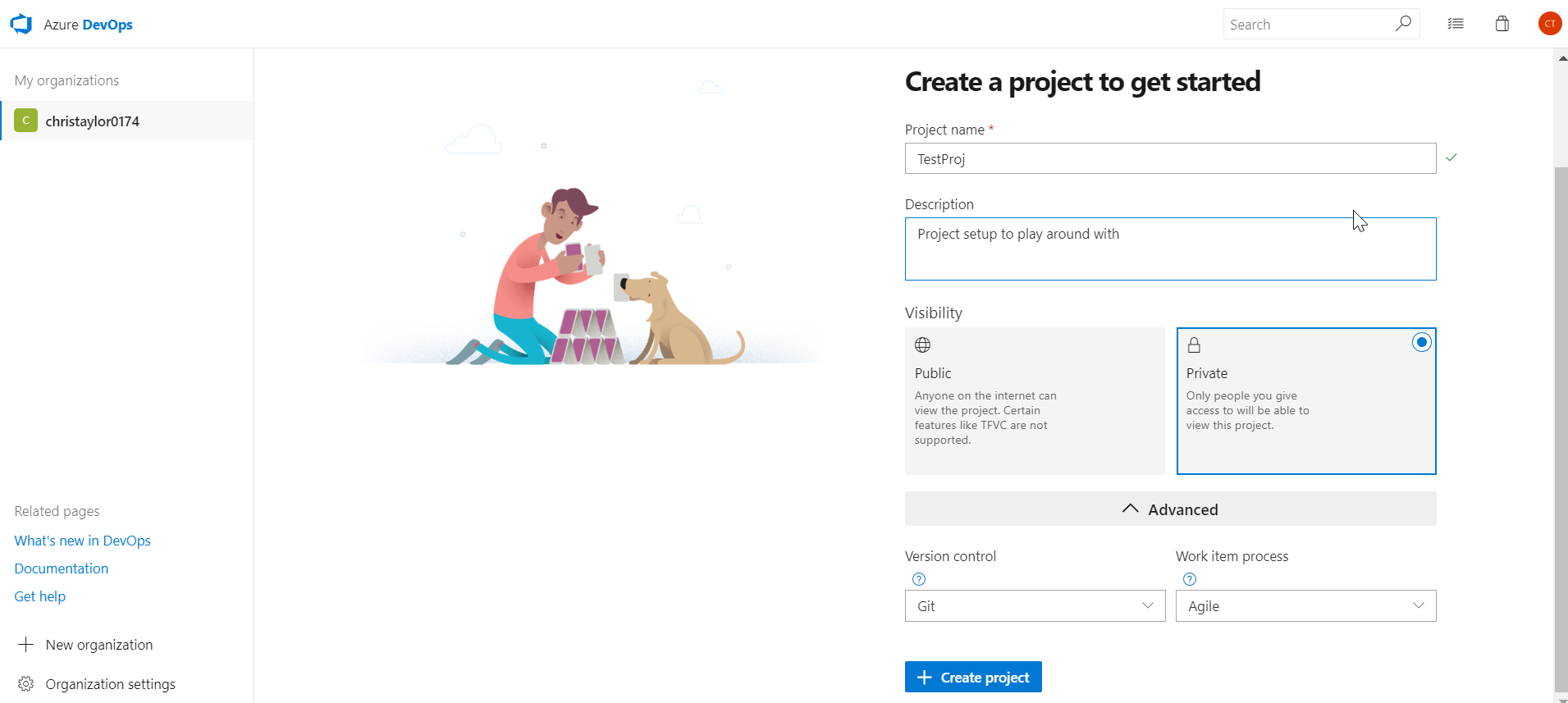
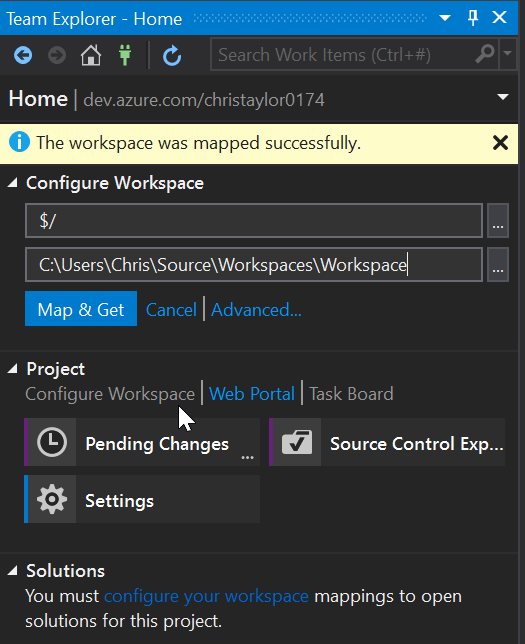
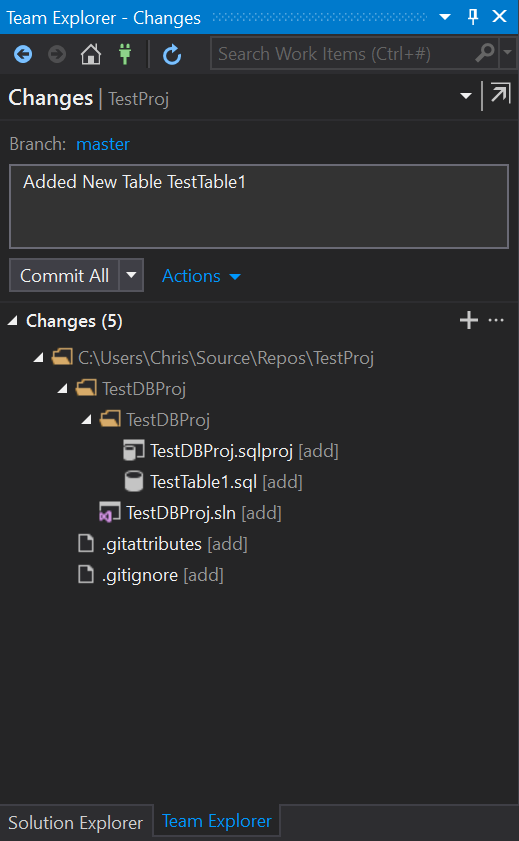
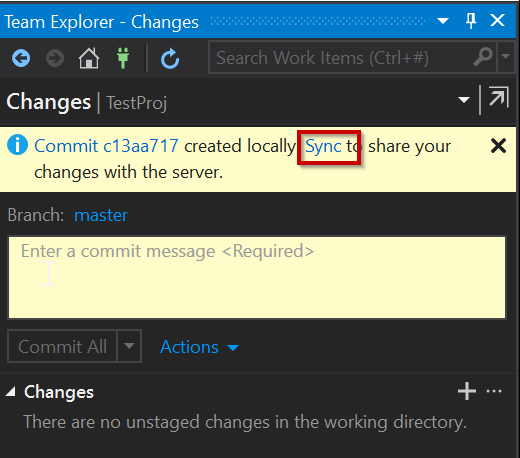
In part 1 of this series we went about setting up our Azure DevOps account, creating a project and adding a Database Project to it. In Part 2 we will look to run through creating a new build pipeline creating a new Docker Image and pushing it to DockerHub.
NOTE: In Part 3 we will change to using Microsoft Container Registry (MCR) for two reasons:
- To highlight the issues with using DockerHub with Azure DevOps
- Because we can 🙂
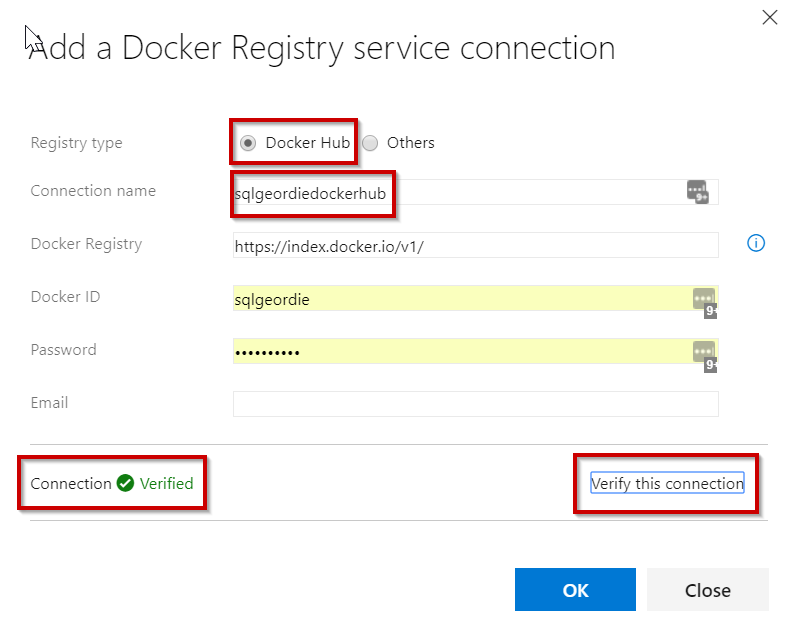
Before we begin creating our build pipeline, it is advised that a Service Connection to Docker Hub (we will also be creating one for Kubernetes in Part 2) is created. This means we aren’t entering passwords / other secure information into our YAML file.
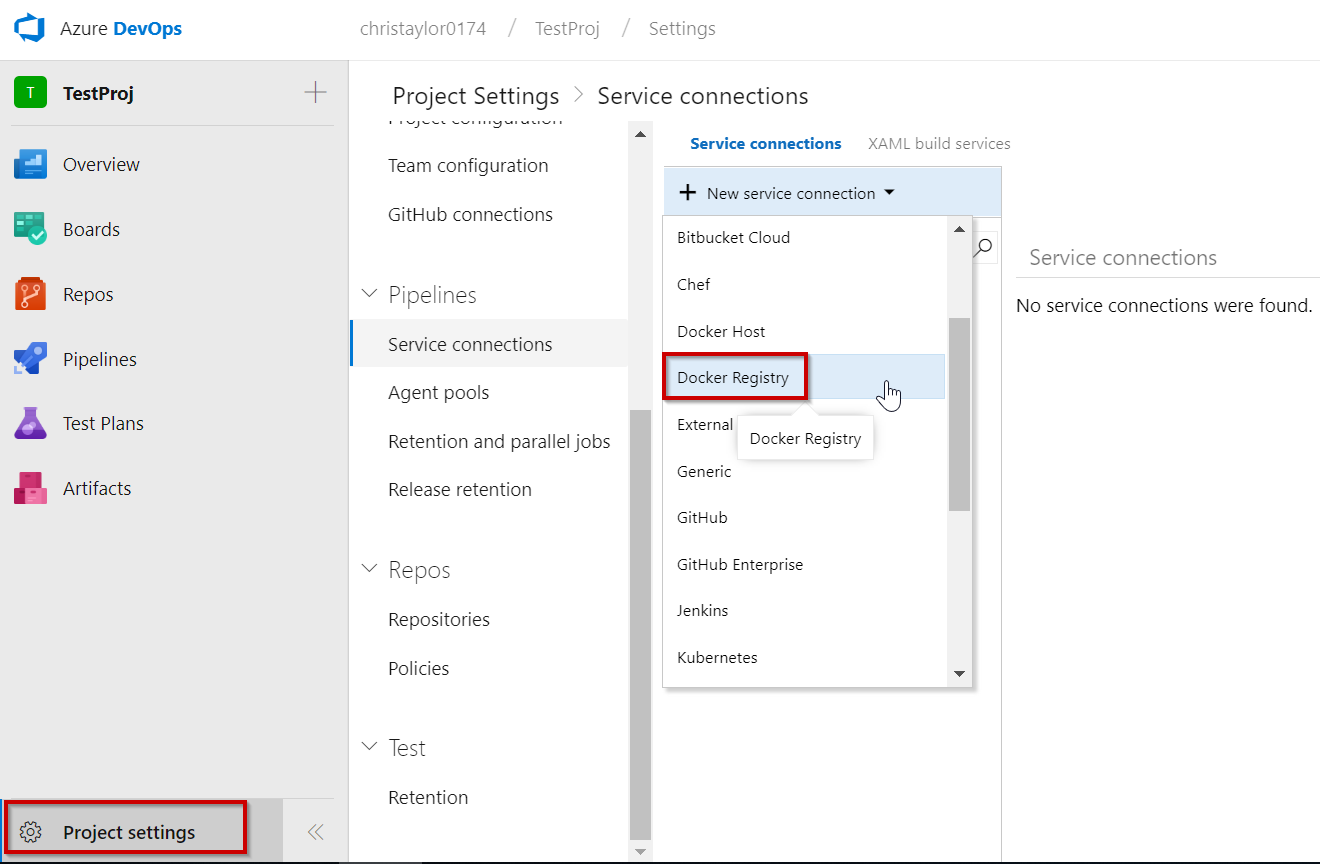
We can do this by selecting Service Connections from the Project Settings. From the image below you can see that there are a large variety of service connections that can be created but we will be choosing Docker Registry:
Simply give the connection a name and enter the Docker ID and Password:
NOTE: once you have created this you need to re-save your pipeline before it will work. This Resource Authorization link provides more information but Microsoft are working improving the user experience on this.
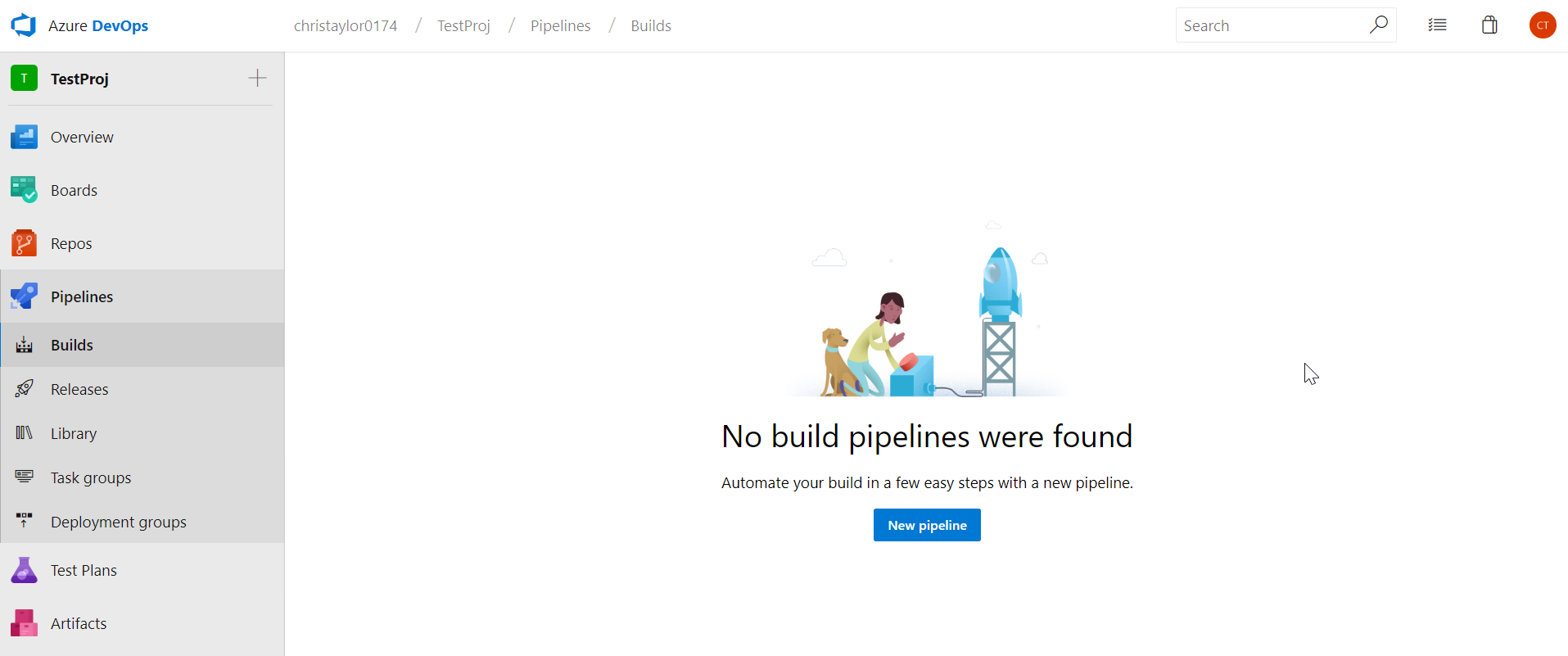
Now that we have created the service connection, we can now look to create our Build Pipeline. Select Builds from the menu on the left and click “New Pipeline”
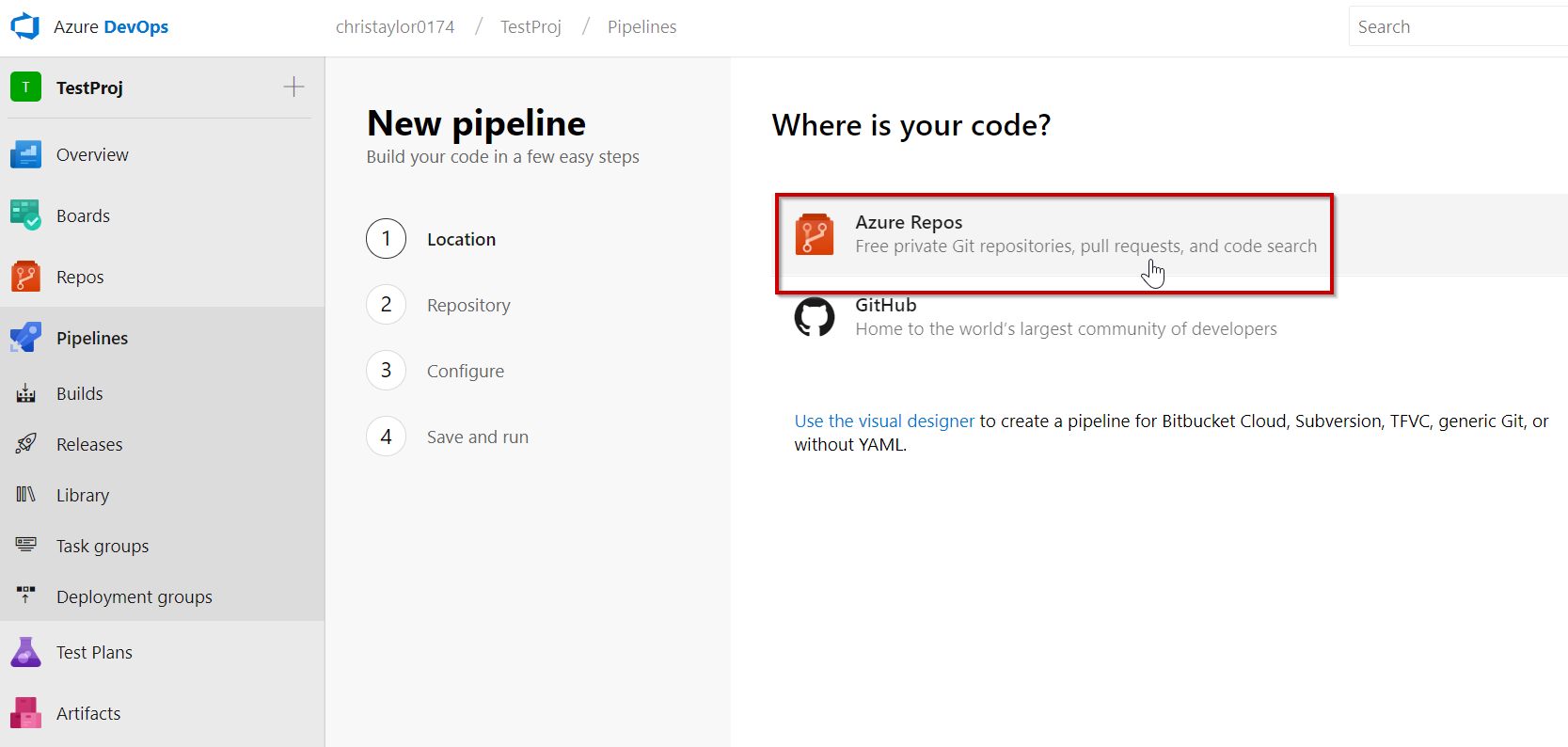
Select the repository where the project you wish to build resides, in our case it is Azure Repos:
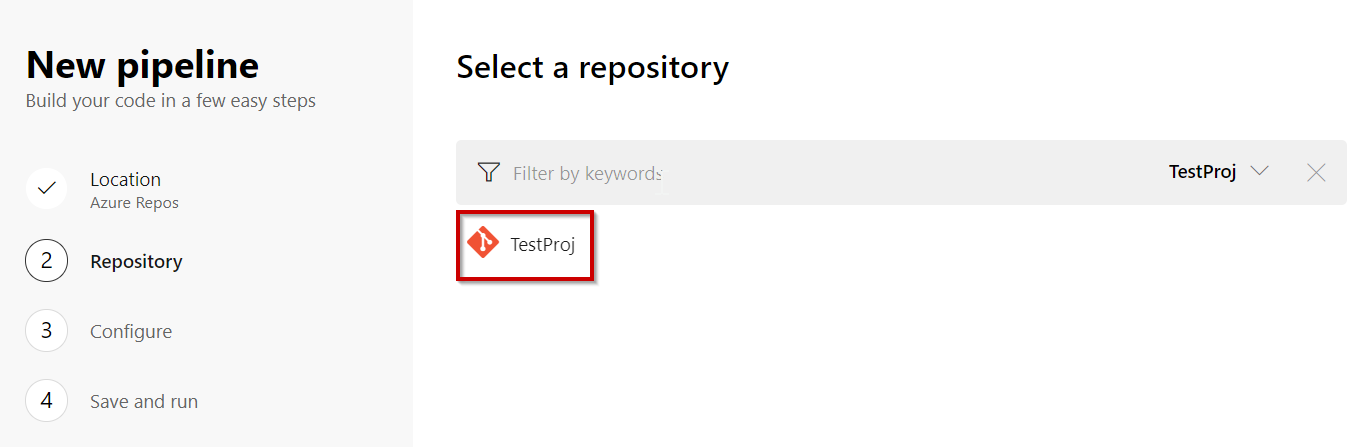
Select the project we have created – TestProj”:
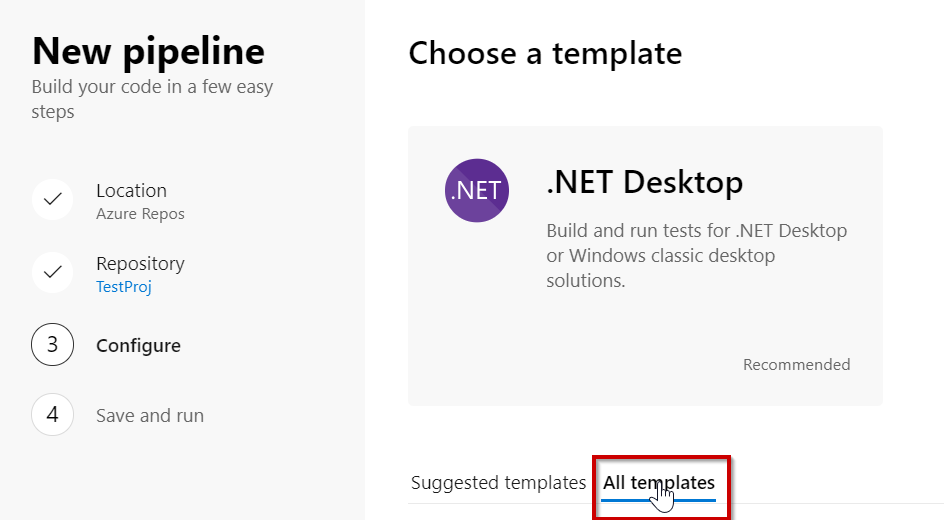
You will now be presented with the option to use a Build Pipeline template or start from scratch.
One of the templates is “Docker Image” so we will choose that one:
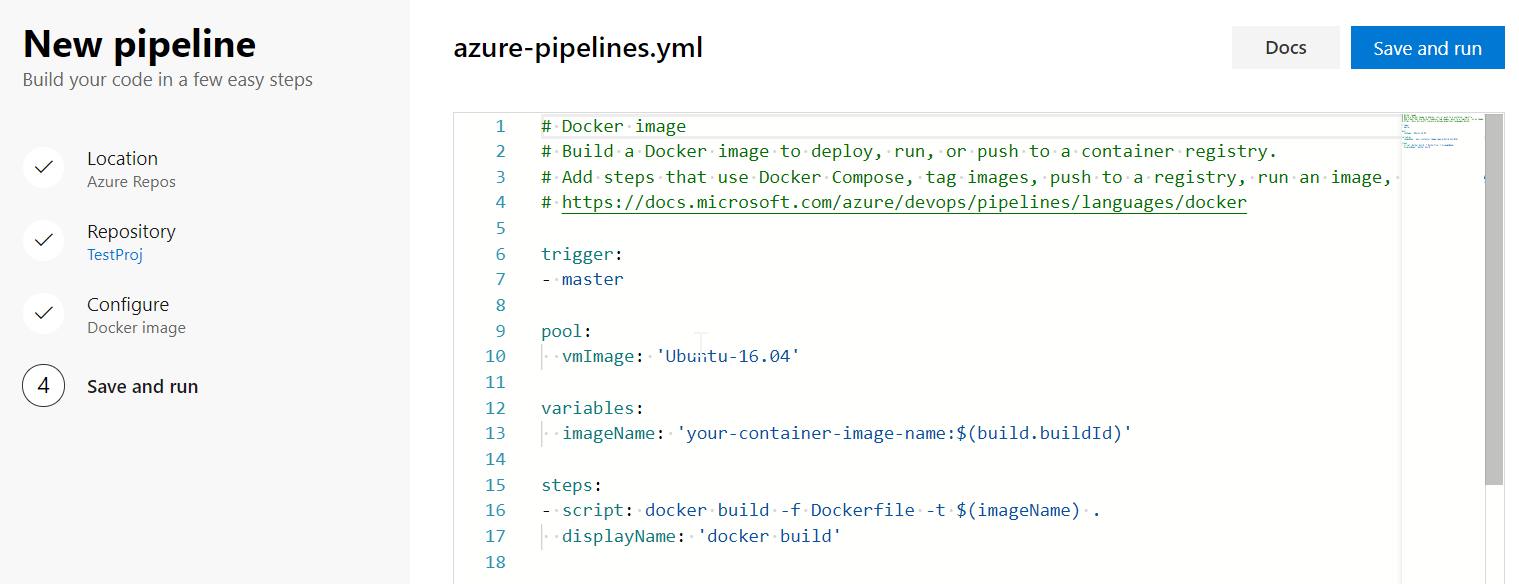
This will auto generate some YAML code to get you started:
As we are using DockerHub as opposed to MCR we have to make a change to the azure-pipelines.yml file which will be used.
This link provides more information but in short we need to change the filename:
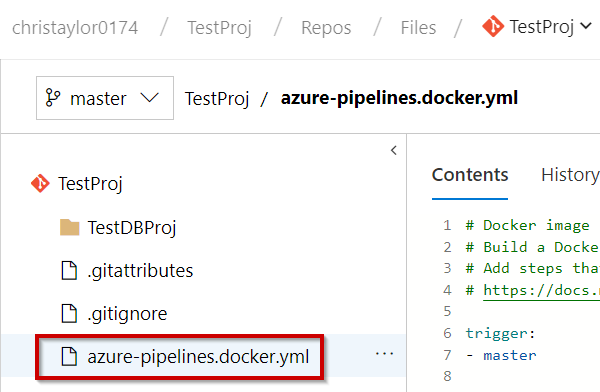
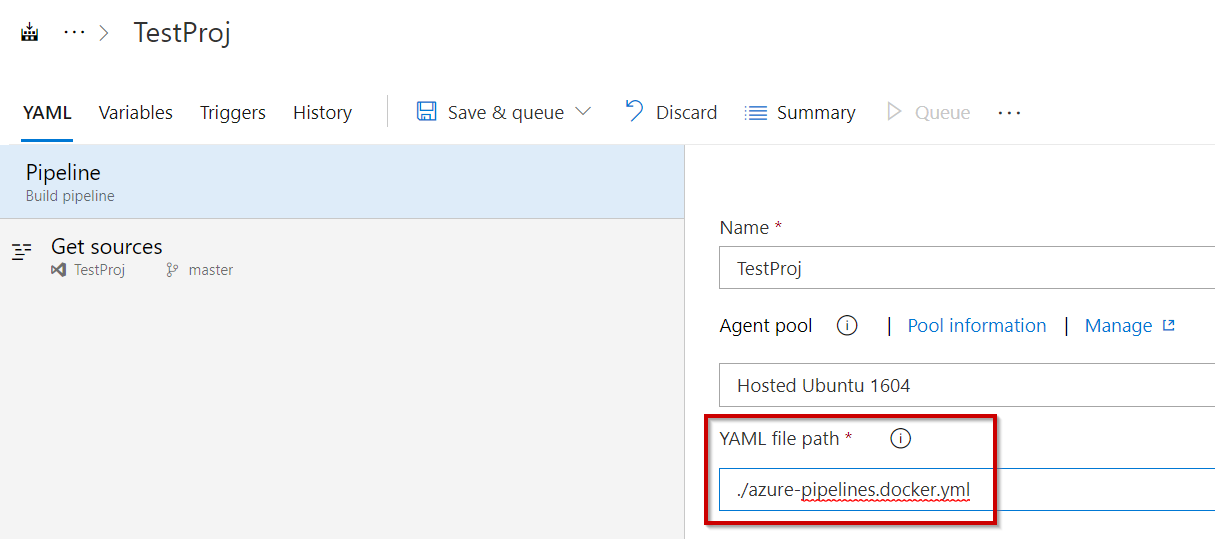
If you have a Docker Hub account, and you want to push the image to your Docker Hub registry, use the web UI to change the YAML file in the build pipeline from azure-pipelines.yml to azure-pipelines.docker.yml. This file is present at the root of your sample repository.
https://docs.microsoft.com/en-gb/azure/devops/pipelines/languages/docker?view=azure-devops&tabs=yaml#example
Once you have made the change, annoyingly you don’t seem to be able to exit from the file with a simple “Save”, you have to “Save And Run”, which will initiate a failed build.
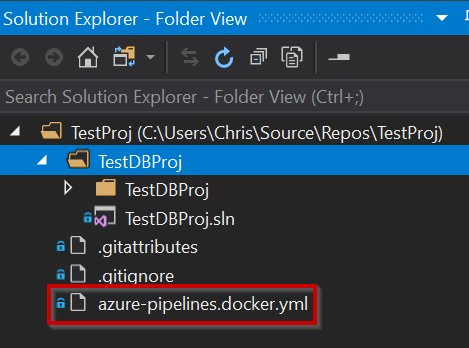
You
can pull the latest changes locally and view/change the file in VS if you
prefer:
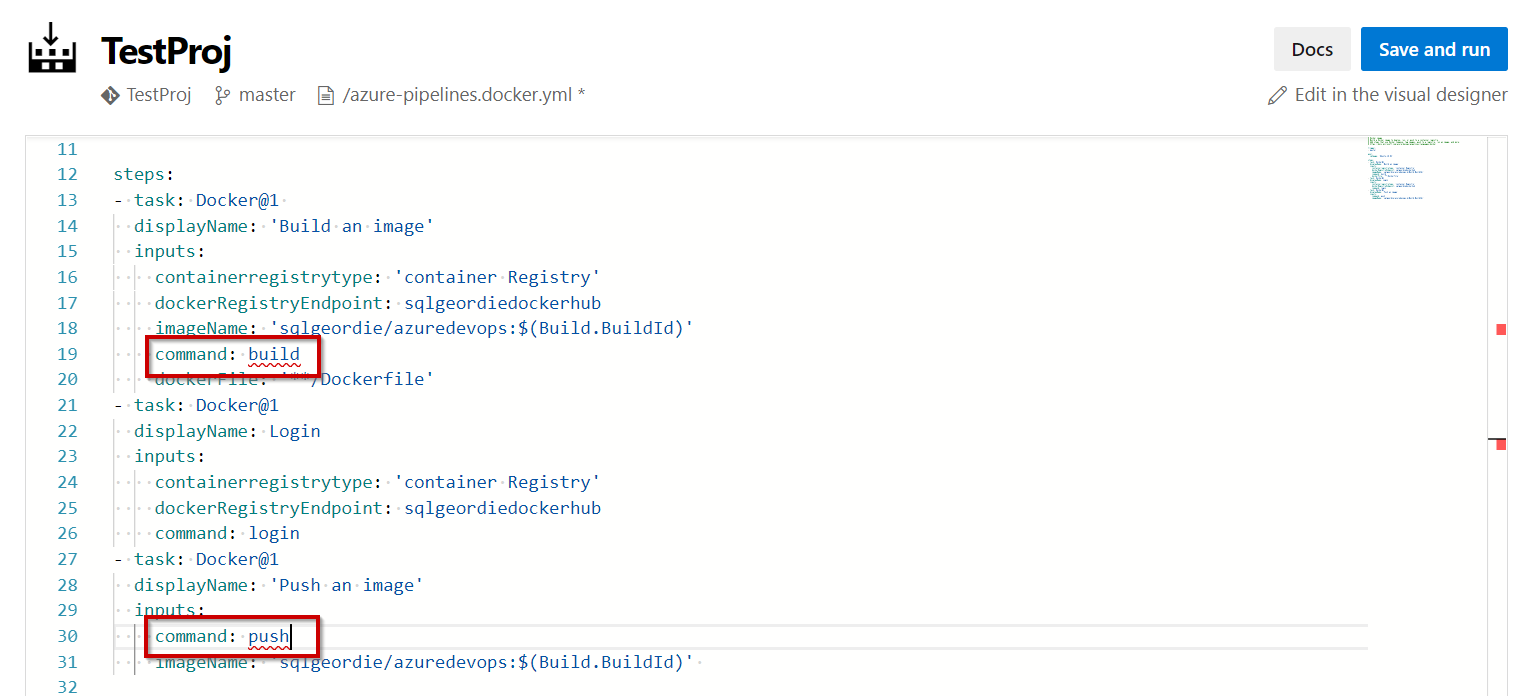
NOTE: You will also need to update the Pipeline to use the new file. You can do this using the Visual Editor:
So, we now have our YAML file name updated and commited as well as the build pipeline updated to use it. However, before we proceed we need an actual Docker image and push that to our Docker Hub repo
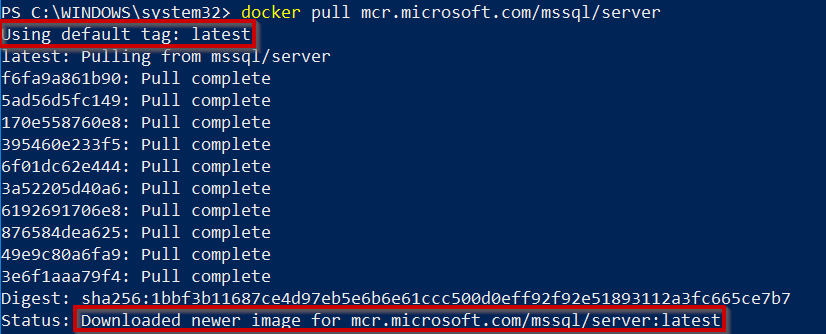
Pull latest SQL Server 2019 on Linux image to local repository:
docker pull mcr.microsoft.com/mssql/server #This will pull the latest version
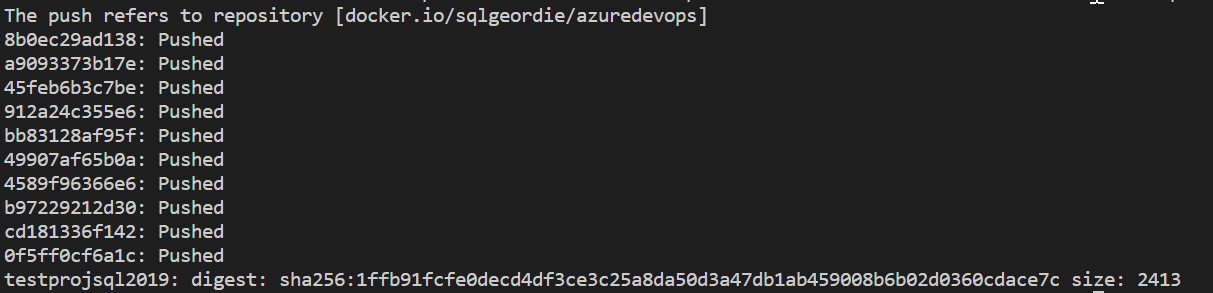
Now push this image up to Docker Hub giving it the tag “testprojsql2019“:
docker tag mcr.microsoft.com/mssql/server:latest sqlgeordie/azuredevops:testprojsql2019
docker push sqlgeordie/azuredevops:testprojsql2019
Using VSCode for output:
We’re not quite ready to run our build, the build pipeline doesn’t create a Dockerfile so we need to create this ourselves. If we don’t we get this error:
"unable
to prepare context: unable to evaluate symlinks in Dockerfile path:" lstat
/home/vsts/work/1/s/Dockerfile: no such file or directory
Dockerfile
FROM sqlgeordie/azuredevops:testprojsql2019
RUN mkdir -p /usr/src/sqlscript
WORKDIR /usr/src/sqlscript
CMD /bin/bash
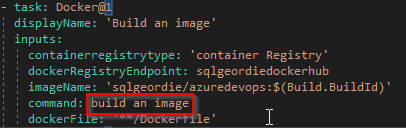
Now, we have to amend the YAML file to login in to DockerHub for us to be able to pull down the image in order to build using the Dockerfile. You will notice in the image below that i have highlighted “build an image”, the reason for this is relevant in the next section.
Build input:
steps:
task: Docker@1
displayName: 'Build an image'
inputs:
containerregistrytype: 'container Registry'
dockerRegistryEndpoint: sqlgeordiedockerhub
imageName: 'sqlgeordie/azuredevops:$(Build.BuildId)'
command: build an image
dockerFile: '**/Dockerfile'
Login input:
task: Docker@1
displayName: Login
inputs:
containerregistrytype: 'container Registry'
dockerRegistryEndpoint: sqlgeordiedockerhub
command: login
Push Input:
task: Docker@1
displayName: 'Push an image'
inputs:
command: push an image
imageName: 'sqlgeordie/azuredevops:$(Build.BuildId)'
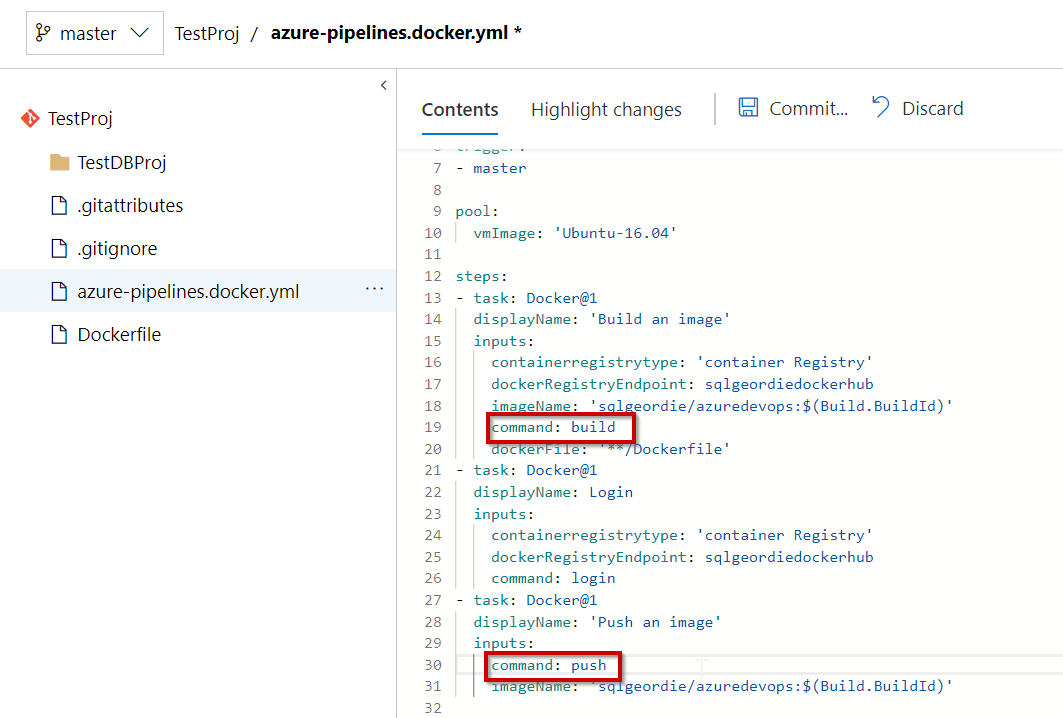
There are examples on GitHub docs which have (in my opinion) errors. For example, I mentioned earlier that I highlighted “build an image” for a reason, that reason is that it is incorrectly stated as “build” (also the same for “push”) on GitHub and this gives errors.
Complete YAML File
#Docker image
#Build a Docker image to deploy, run, or push to a container registry.
#Add steps that use Docker Compose, tag images, push to a registry, run an image, and more:
#https://docs.microsoft.com/azure/devops/pipelines/languages/docker
trigger:
- master
pool:
- vmImage: 'Ubuntu-16.04'
steps:
- task: Docker@1
displayName: 'Build an image'
inputs:
containerregistrytype: 'container Registry'
dockerRegistryEndpoint: sqlgeordiedockerhub
imageName: 'sqlgeordie/azuredevops:$(Build.BuildId)'
command: build an image
dockerFile: '**/Dockerfile'
- task: Docker@1
displayName: Login
inputs:
containerregistrytype: 'container Registry'
dockerRegistryEndpoint: sqlgeordiedockerhub
command: login
- task: Docker@1
displayName: 'Push an image'
inputs:
command: push an image
imageName: 'sqlgeordie/azuredevops:$(Build.BuildId)'
The “incorrect” example in the docs is:
- task: Docker@1
displayName: Build image
inputs:
command: build
azureSubscriptionEndpoint: $(azureSubscriptionEndpoint)
azureContainerRegistry: $(azureContainerRegistry)
dockerFile: Dockerfile
imageName: $(Build.Repository.Name)
The strange thing is that if you edit the file directly online there is no error:
However, if you edit the pipeline you see the red syntax error “squiggle“:
Please make sure you change this otherwise you will receive and error in your build.
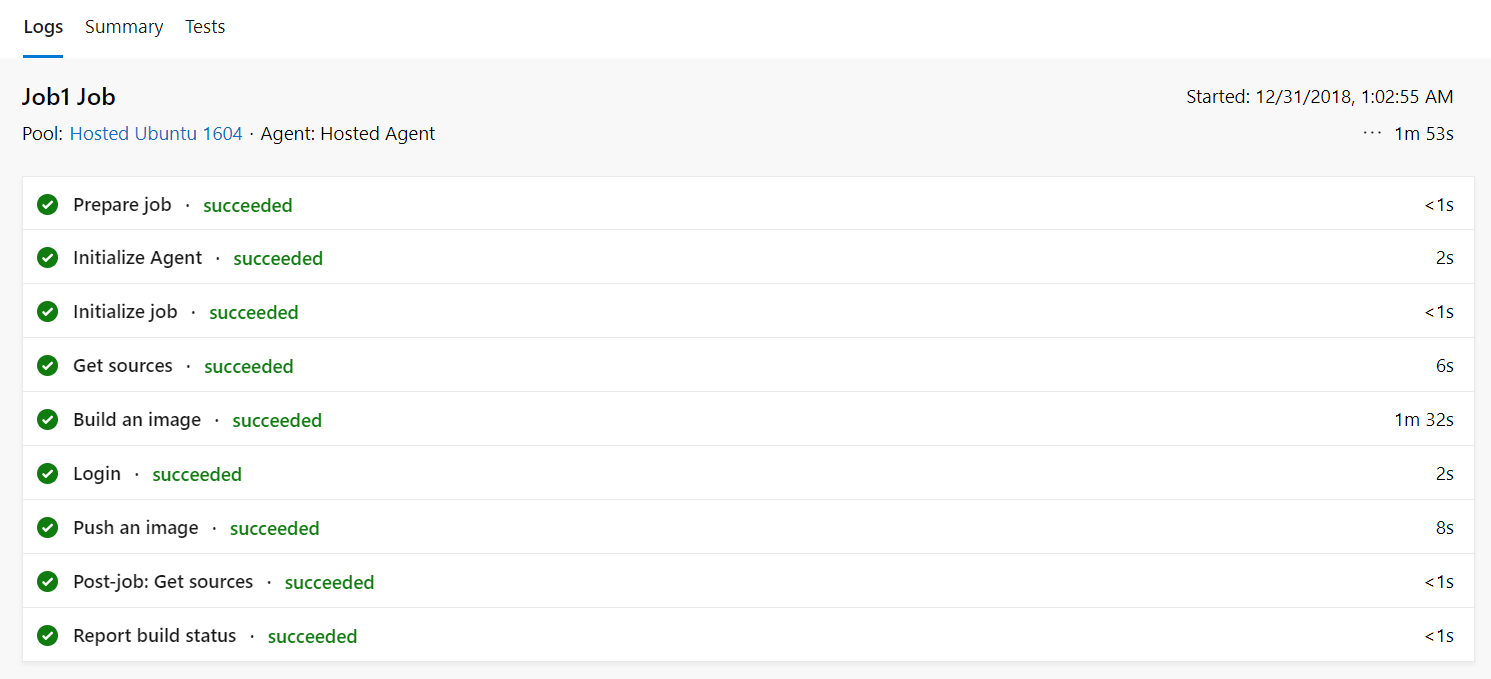
To get back on track, in theory, we should now be able to run the build which will pull the image from our DockerHub repository, and initiate building a new Docker image from our Dockerfile (granted a very basic build) and push it back up to DockerHub
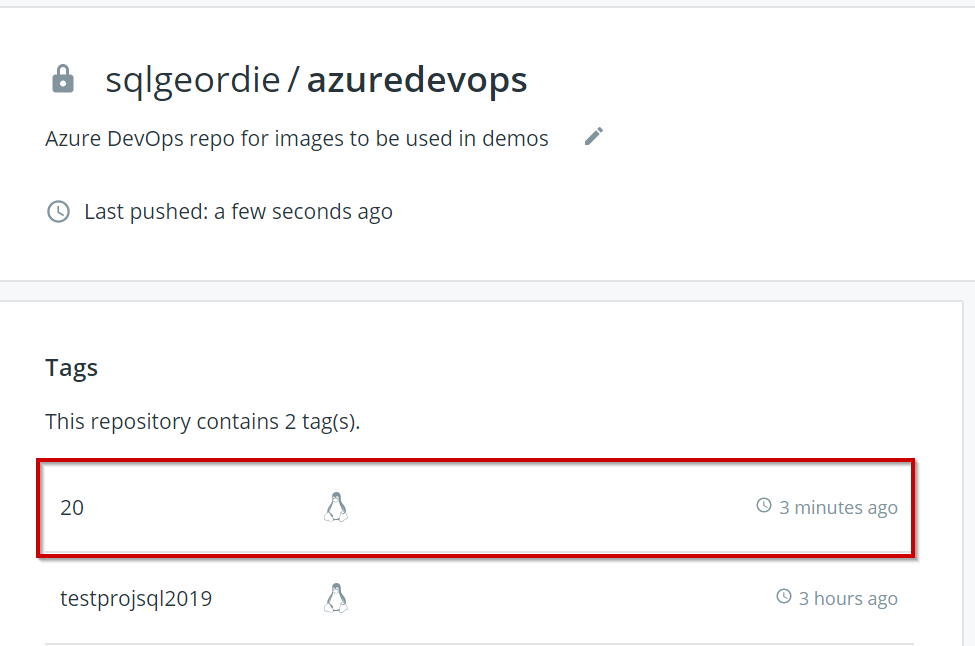
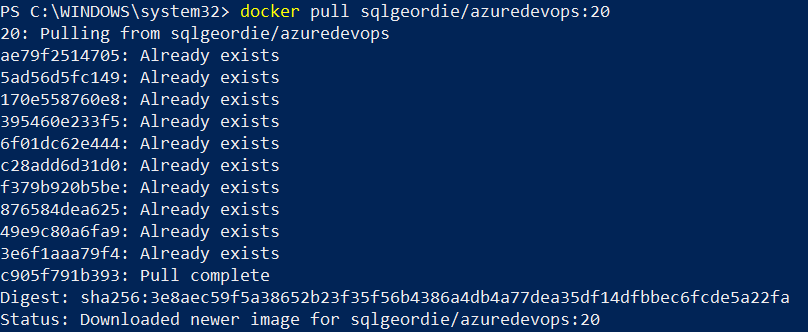
We can now check the image exists in Docker Hub:
Pull
it down:
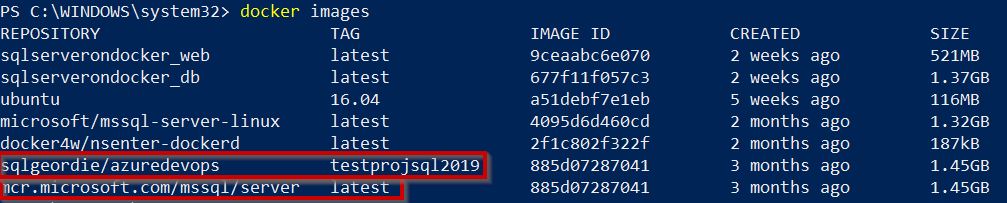
Check local images:
There we have it, we have successfully built a new Docker image from a Dockerfile which resides on DockerHub and pushed the newly created image back to DockerHub.
In the Part 3 we will look to expand on this and look to incorporate it into the TestProj we created in Part 1 and show how we can push changes made to our TestDBProj to Azure DevOps to initiate a build process to provide a new Docker Image with our changes applied.
I have created some videos (no audio I’m afraid) of this process which was used as part of my sessions at Data In Devon and DataGrillen earlier this year. I will be looking to replace these with either a full blog post (ie. Part 3) or perhaps re-record the videos with audio.