
For video demos please see: Database CI/CD with Containers (Docker) and Azure DevOps (Demo’s – YouTube)
Introduction
I decided to throw together some steps on how you can start utilising SQL Server running on Linux in a Docker container a little more than just doing a docker run, connecting via SSMS/sqlcmd, running a few commands then blowing it away and saying you now know docker 🙂
DevOps, CI/CD, automation, whatever you want to call it is a massively hot topic at the moment and I’ll be running through how you can get yourself started with a database project (.sqlproj) and source control using Azure Repo (Repository). We will then run through how to take a Docker image (this can be stored in Dockerhub or Microsoft Container Registry) and push any changes to this via an Azure DevOps build pipeline to create a new Docker image with your changes applied. For the purposes of this blog post I will be using DockerHub but Part 3 will be using the Microsoft Container Registry (MCR) due to issues I have discovered in the Deployment pipeline in Azure DevOps meaning that I can’t use DockerHub.
This is quite a lengthy post so I will save the Deployment pipeline to run the newly created image in a Kubernetes cluster ready for UAT, Pre-Prod or even Production (if you’re brave enough) for part 3. Or, if you’re in Exeter for Data in Devon on Saturday April 27th, or DataGrillen on Thursday/Friday 20th/21st June then come and see my session where we will delve a bit more into this.
Seeing as most of this will be run in Azure, there are small costs associated with running the Kubernetes cluster but everything else in part 1 and part 2 are (at the time of writing) completely free – so no excuses! the list of tools used are listed below:
- SSDT (Free)
- Azure DevOps including Azure Repo (Free)
- Docker for Windows Community Edition (CE)
- DockerHub (Free, Ts&Cs apply)
- Azure Kubernetes Service (AKS) (Not Free but costs can be kept low)
Install SSDT
First off, in order to create our Database Project (sqlproj) then we will need to download and install SQL Server Data Tools. This will install a Visual Studio Shell so you don’t necessarily need a full blown edition of Visual Studio. You can download it here.
Setup Azure DevOps Account
Azure DevOps is a one stop shop for your Development life cycle requirements and can simplify the automation of an entire continuous integration (CI) and continuous delivery (CD) pipeline to Azure . There are several tools within it including:
- Boards
- Pipelines
- Repos
- Test Plans
- Artifacts
There are paid for aspects of Azure DevOps. For example if you wish to make an Artifact available to teams larger than 5 users then you will have to pay $30/mth. Everything we will be using here is free!
To get started, you will need to create an account or if you have one already, sign in:

Once you have created your account and went through the various authentication/verification, you can start creating a project in Azure Repo. In the screen shots below you can see that even a Private repo is free which is fantastic!
Give it a name and Description if you wish and choose a version control type. I have chosen Git because that’s what all the cool kids are using.
Congratulations! Your project is now created and ready to connect to using VS / SSDT.
Connect using Visual Studio 2017
You can connect directly to your Azure Repo (Git) project directly from VS, this is done by selecting the Team Explorer menu option:
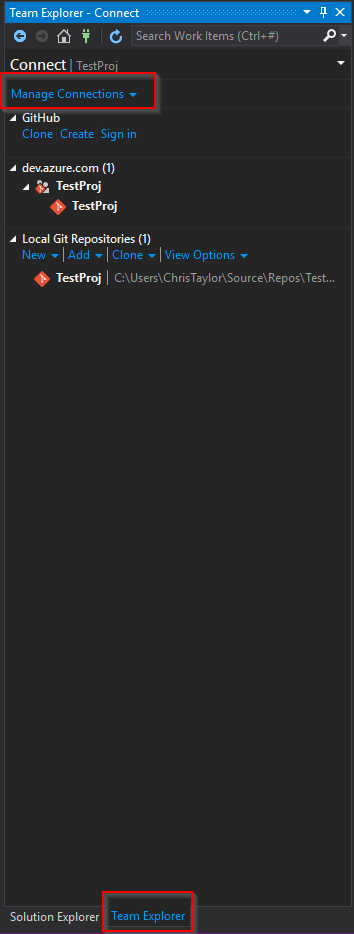
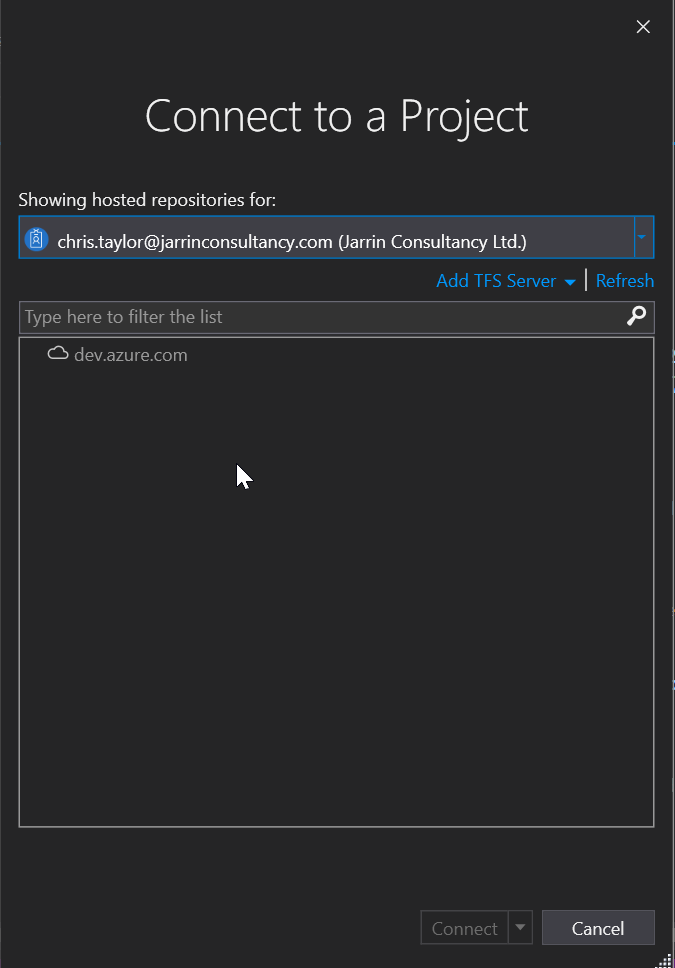
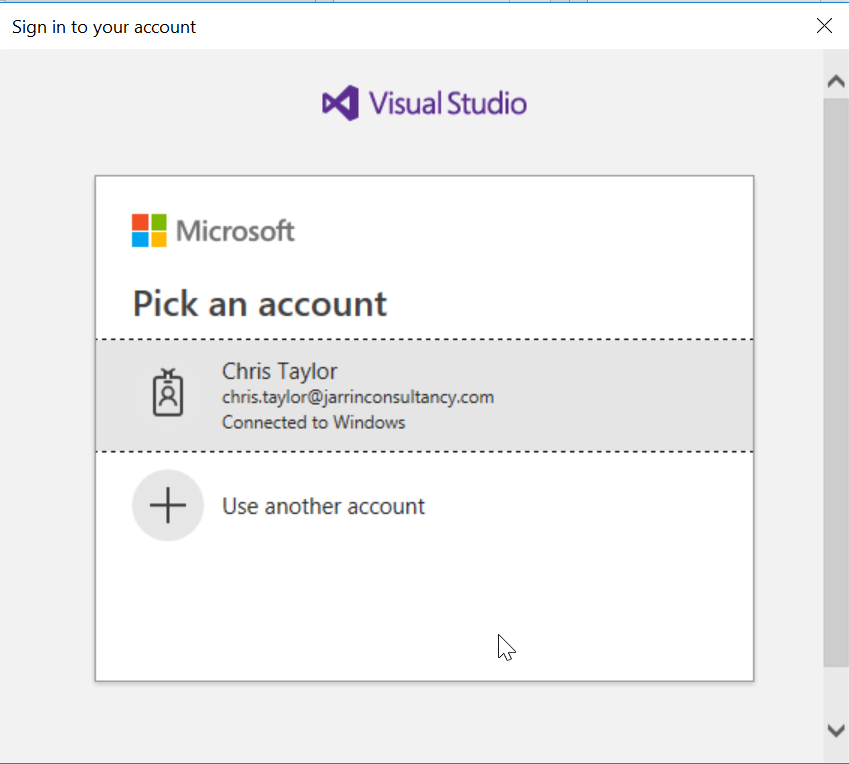
Enter your login details and select the repo
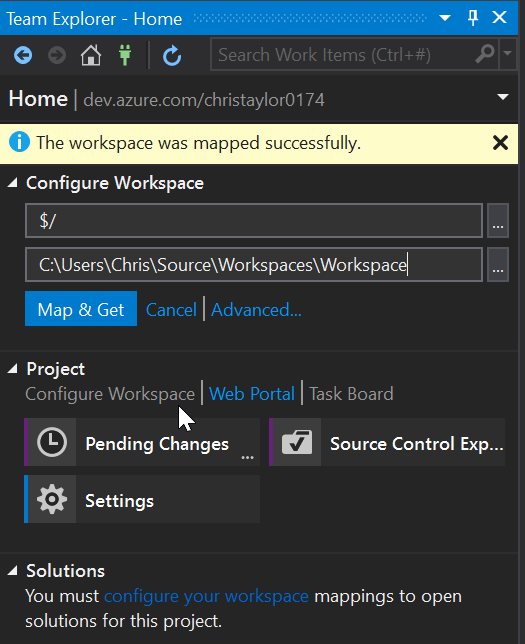
You will have to “Map” the Git Repo to a folder on your local machine, this can be anywhere so choose somewhere suitable.
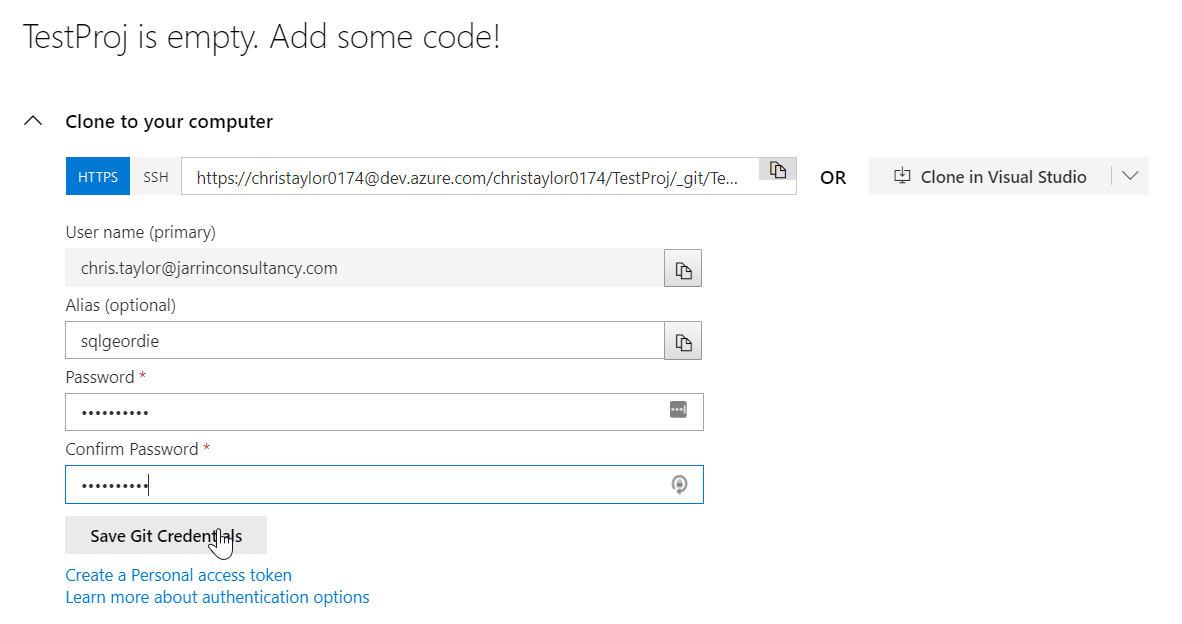
Enter the details you used to create the Azure DevOps account and Save Git Credentials so you won’t have to re-enter these later.
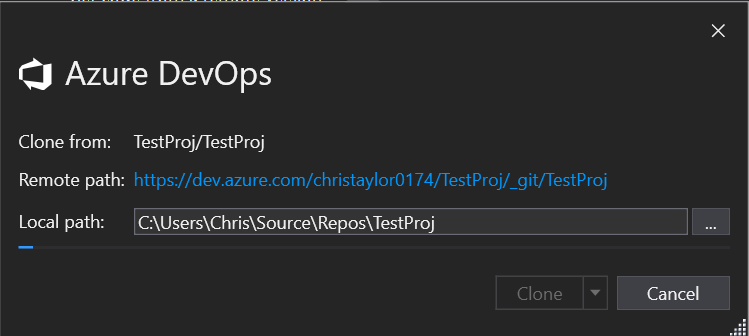
That is it, you are now connected to your Azure Repo so any project you make changes to locally can now be pushed to an online repository!
For this demo I have created a folder in the project called “TestDBProj” in Solution Explorer, this isn’t necessary but I like to try and keep things a little tidy:
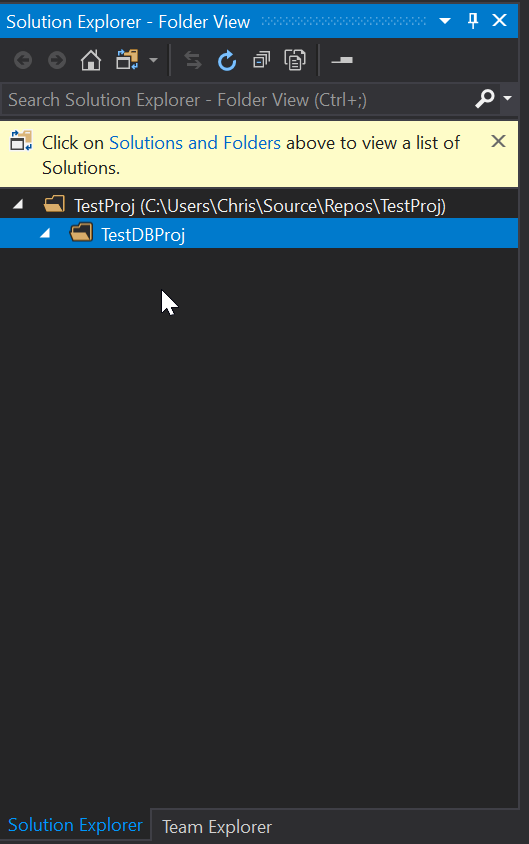
Looking at Team Explorer, everything is now setup and you have now cloned the TestProj project to your local development machine. We can now get started with making a few changes.
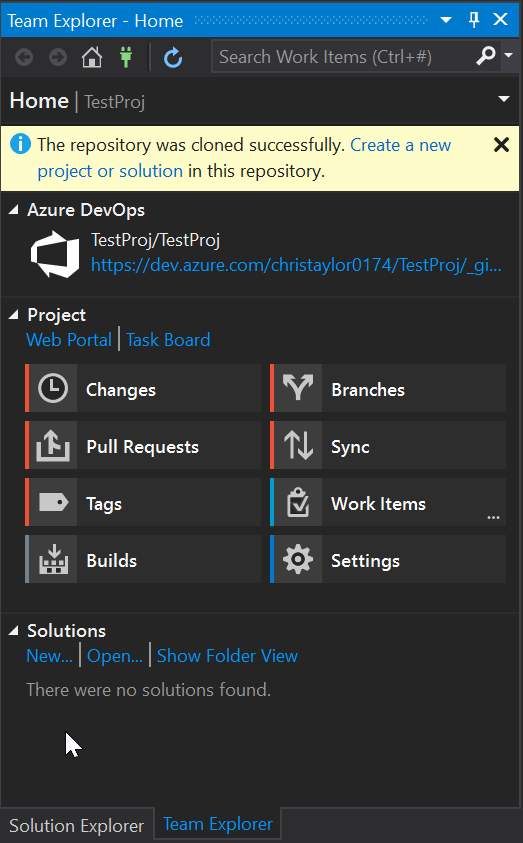
Create Database Project
Seeing as TestProj literally has nothing in it, we need to create a new Database project and we can call it TestDBProj:
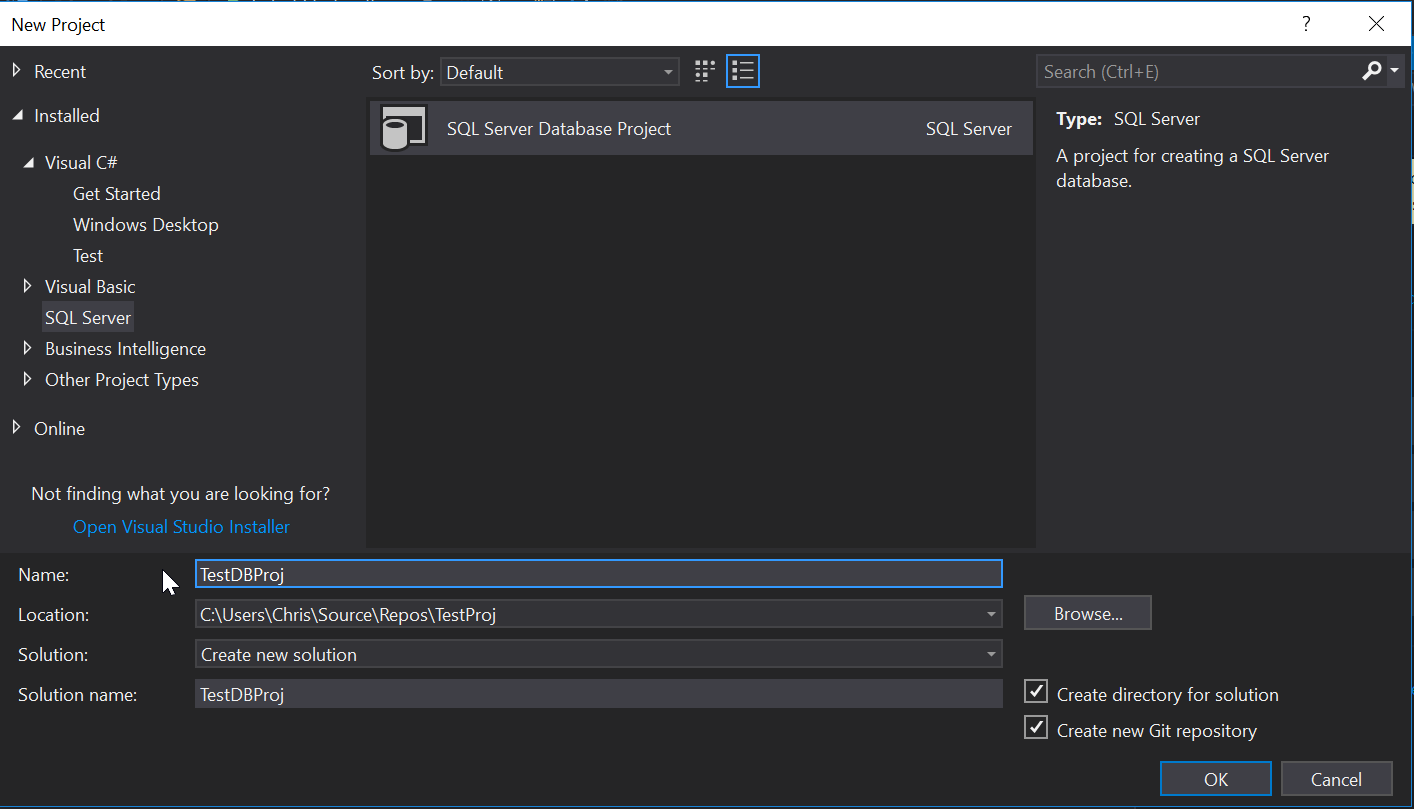
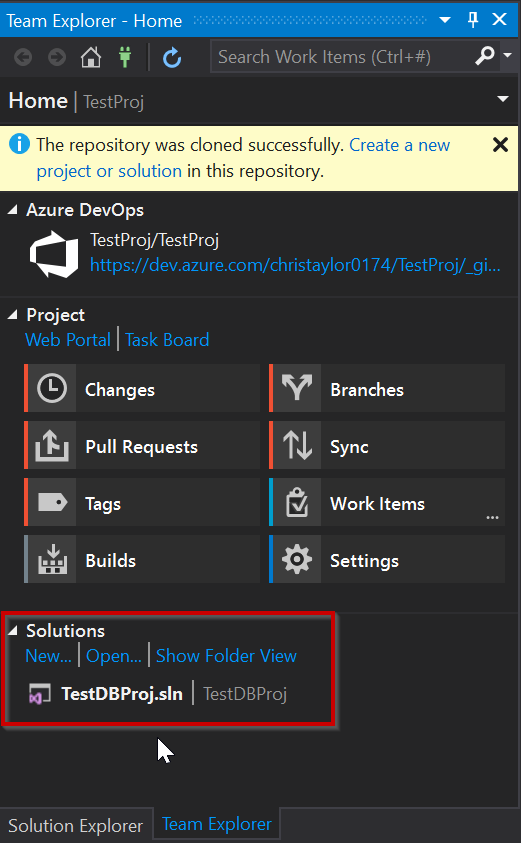
Fantastic, our TestDBProj is now created and we can start adding objects to it. At this point if you have a database schema you need to import you can do that using the schema compare but again, keeping it simple we’ll just add a new table called TestTable1:
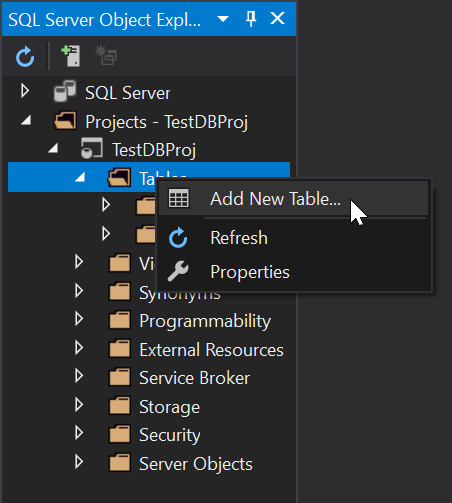
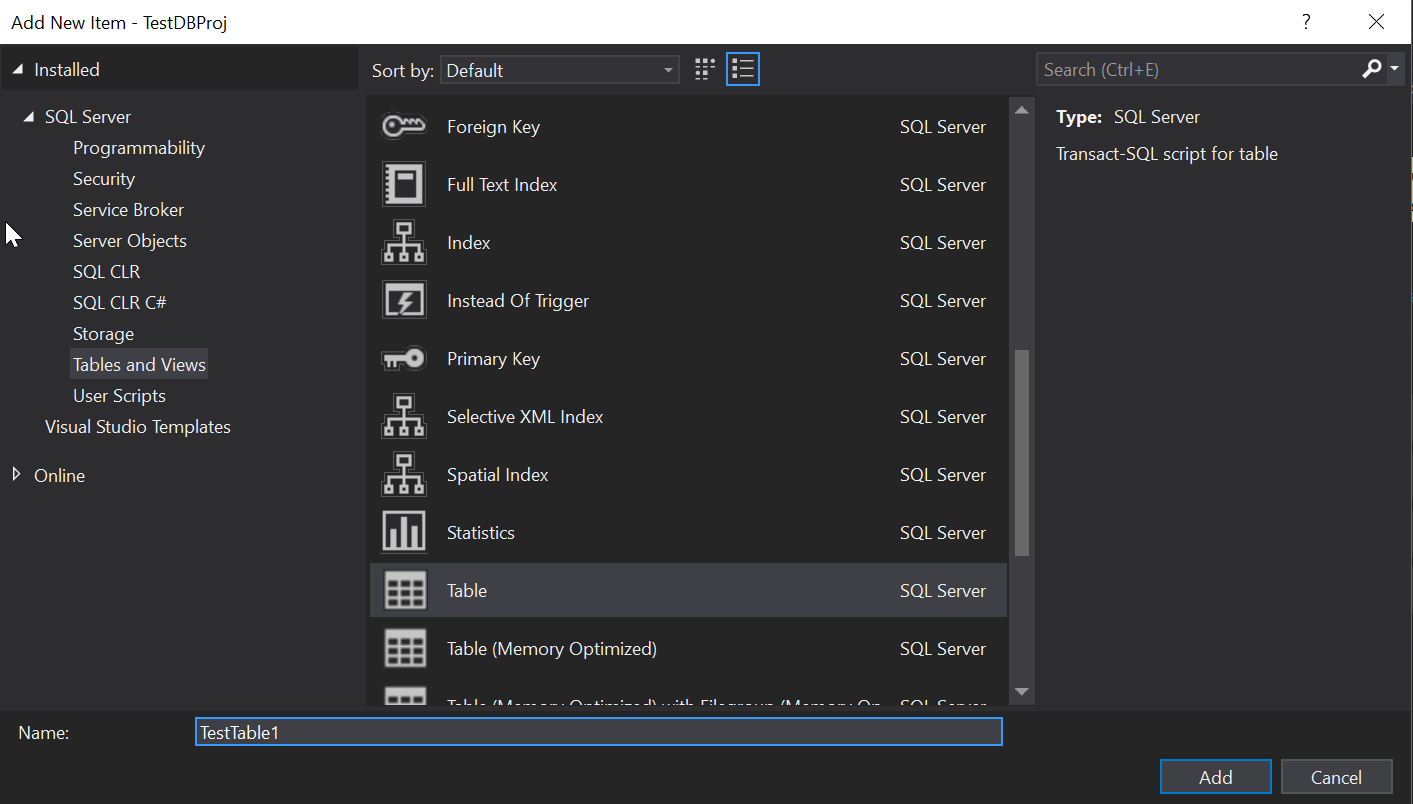
Add a new column called [descr]:
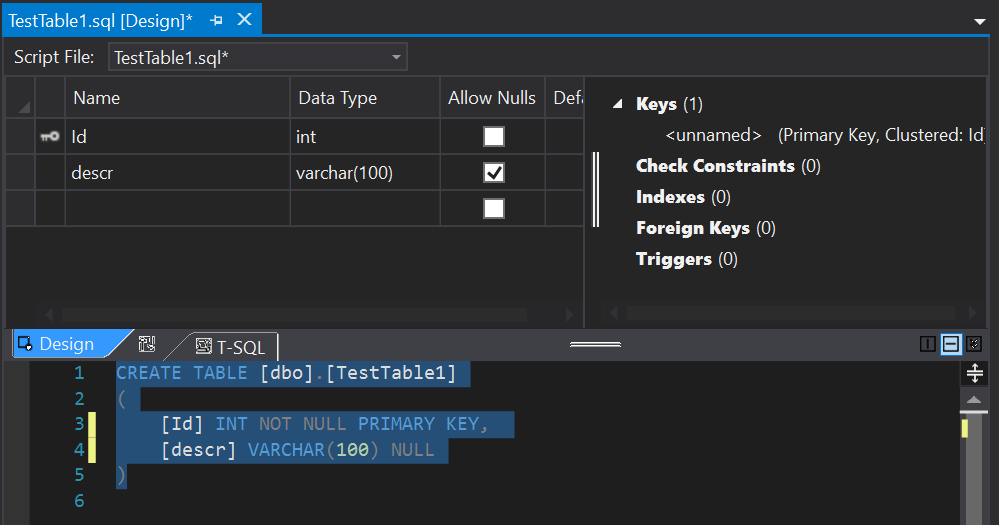
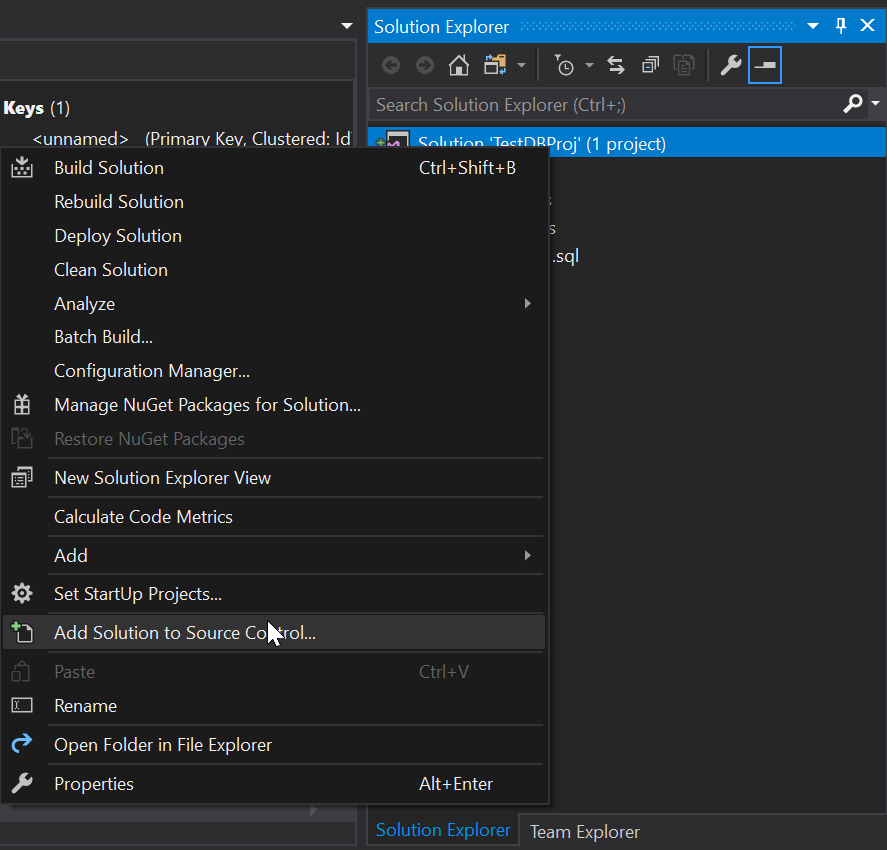
We’ve made some changes but at the moment our project has not been added to Source Control so let’s add it:
Check the changes and commit making sure you add a commit message:
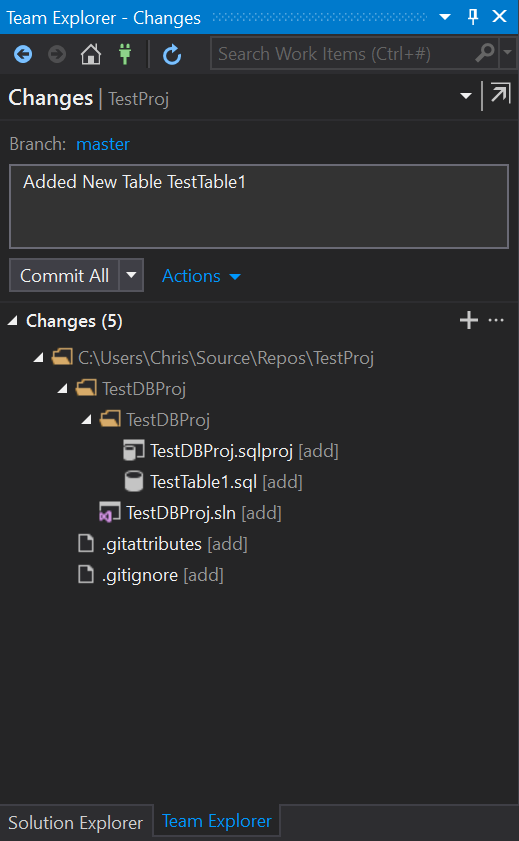
NOTE: This can also be done via command line but as this is an introduction / getting started we are using the Gui.
You should now get a message saying that the changes have now been committed locally:
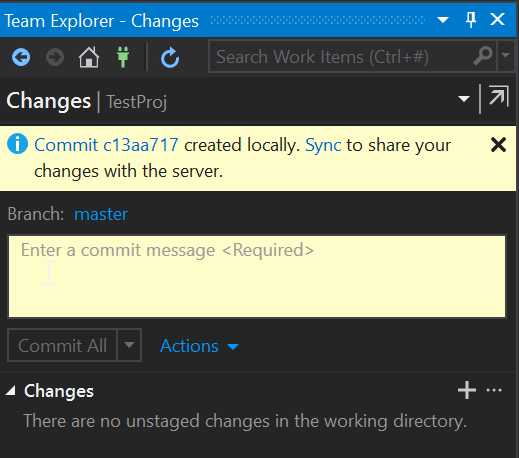
To get the changes into our Azure Repo we need to push them, or in the case of the Gui “Sync” our changes and using “Push”:
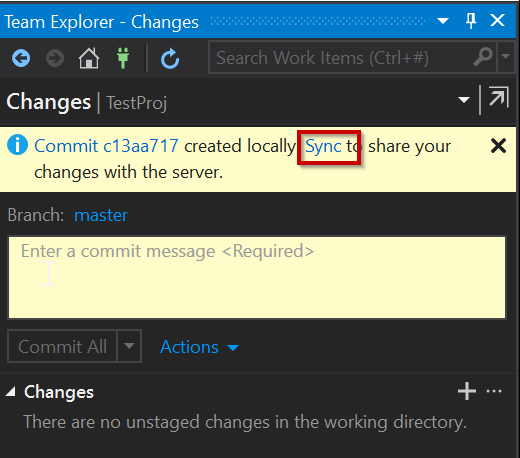
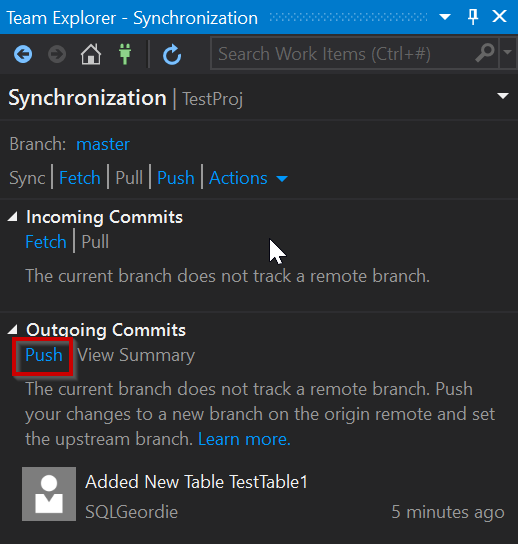
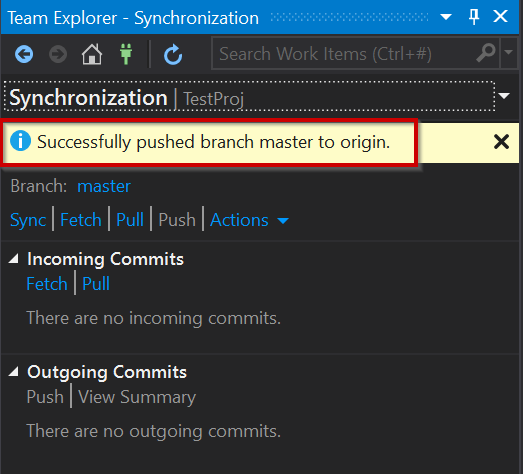
There we have it, our changes have now successfully pushed to our Azure Repo and we can check online and it should now be available:
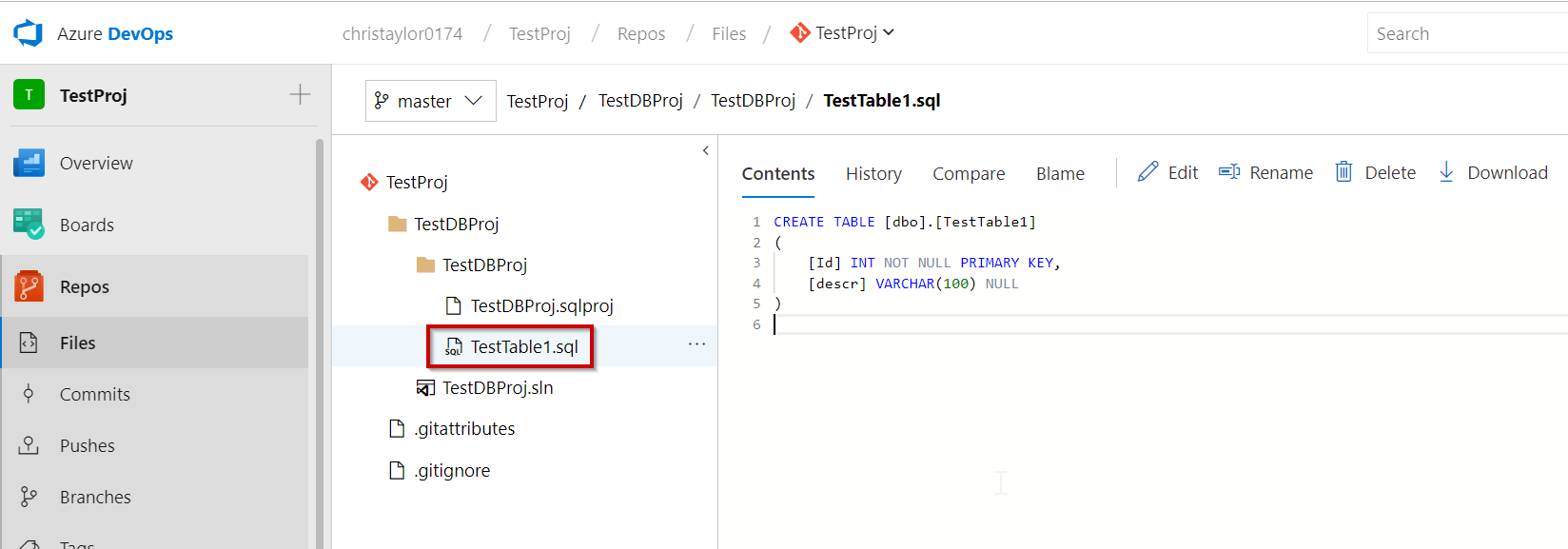
In Part 2 of this series we will start looking at the Azure DevOps Build Pipeline and how to create a new (very basic changes made) Docker Image from an Image stored in DockerHub and push it back.
I have created some videos (no audio I’m afraid) of building an Azure DevOps Pipeline which will create a new docker image with the changes made to the project and deploy it to Kubernetes. These are part of the demos used as part of my sessions at Data In Devon and DataGrillen earlier this year.

One thought on “CI/CD with Docker and Azure DevOps – Part 1 (Creating our Database Project)”
1 Pingback